01
Internal Consistency and Item Sensitivity Analysis (Alpha if Item Deleted)
▼
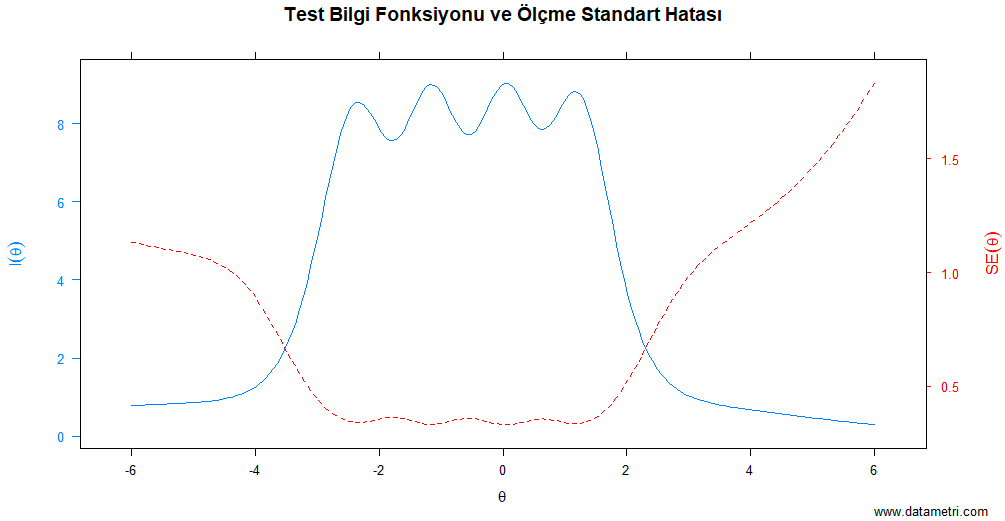
"Test the Resistance of the Measurement Instrument Against Random Errors"
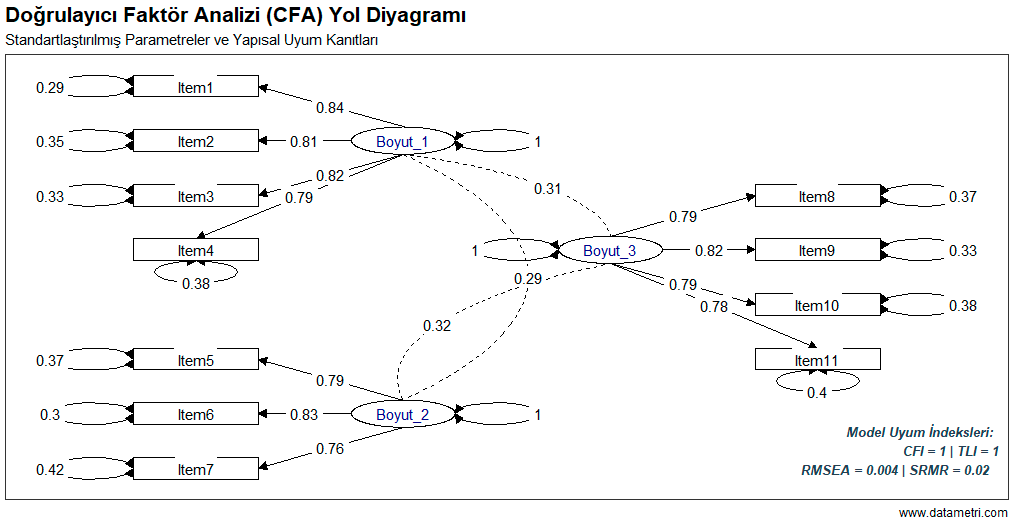
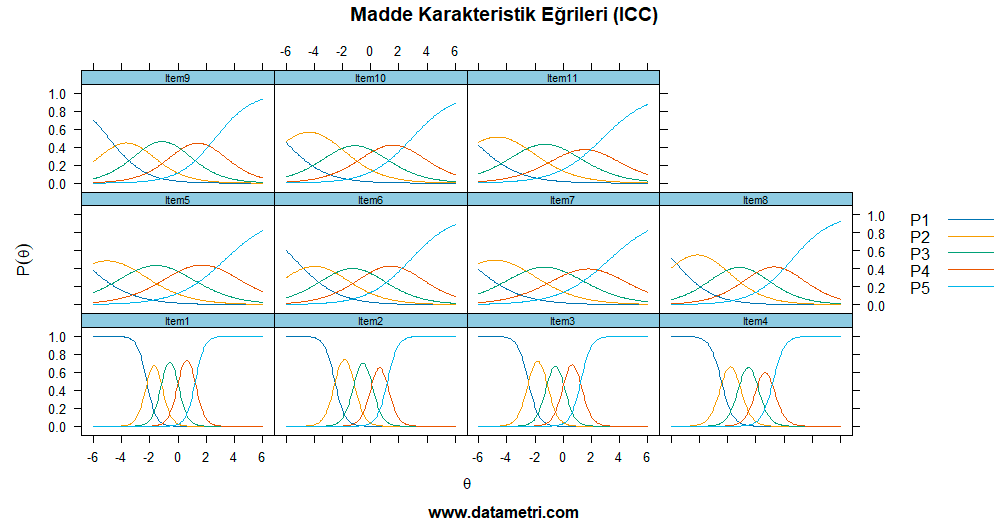
The first step of measurement quality is to determine the marginal effect of the items on total internal consistency. This analysis evaluates the degree to which test items synchronously measure the same latent construct.
Which Questions Does This Analysis Answer?
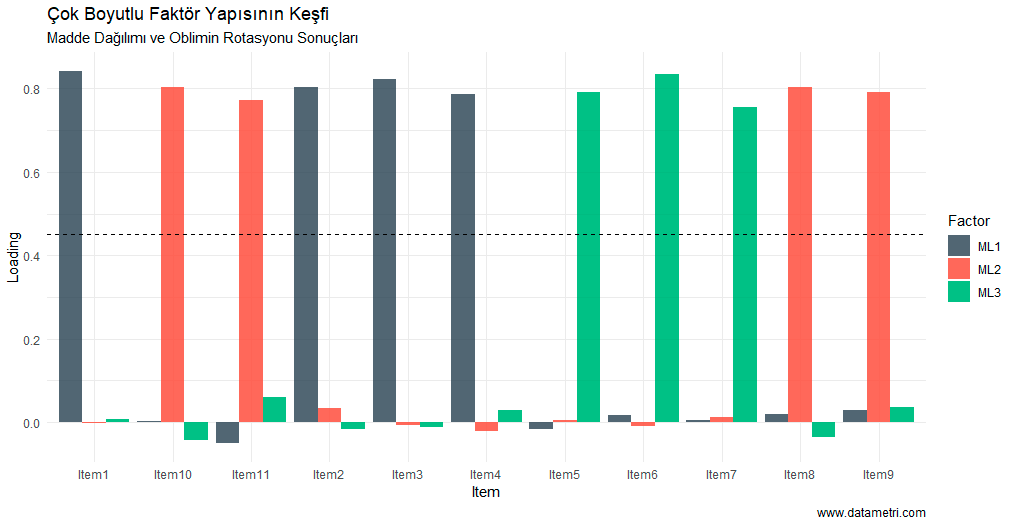
- How harmoniously do the items in my scale work together to measure a single concept (unidimensionality)?
- If we want to shorten the scale (create a short form), sacrificing which items will minimize the loss of reliability?
Added Value to Your Research
In corporate performance or clinical survey systems, identifying "unnecessary" or "misunderstood" questions that cause respondent fatigue reduces data collection costs while maximizing response quality.
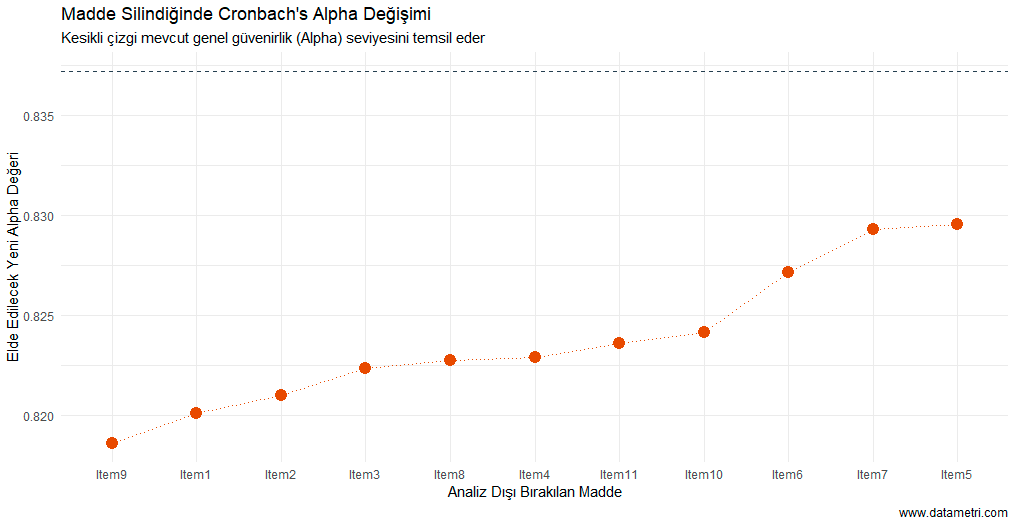
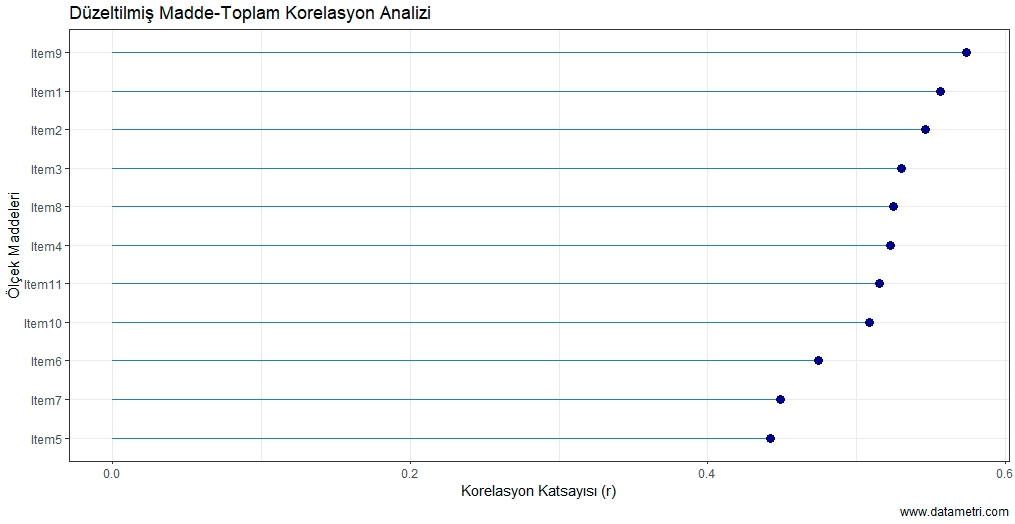
Each data point in the graph shows the new Cronbach's Alpha coefficient produced by the remaining items when the respective item is removed from the scale. The dashed line represents the current overall reliability level. According to the analysis result, the total reliability dropping to its lowest level (0.818) when Item9 is excluded proves that this item is the "core component" of the scale.