01
İç Tutarlılık ve Madde Duyarlılık Analizi (Alpha if Item Deleted)
▼
"Ölçüm Aracının Tesadüfi Hatalara Karşı Direncini Test Edin"
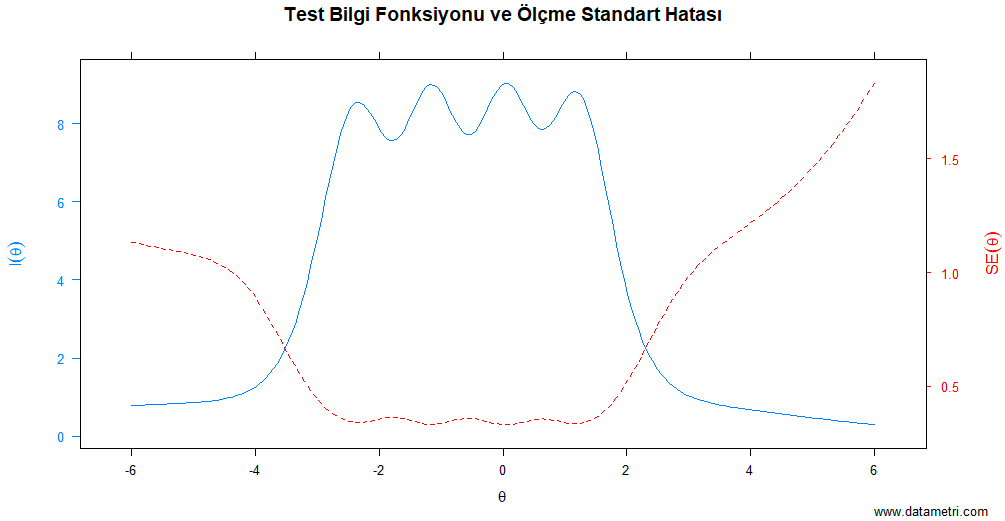
Ölçme kalitesinin ilk adımı, maddelerin toplam iç tutarlılık üzerindeki marjinal etkisini belirlemektir. Bu analiz, test maddelerinin (items) aynı örtük yapıyı (latent construct) ne derece senkronize ölçtüğünü değerlendirir.
Bu Analiz Hangi Sorularınıza Cevap Verir?
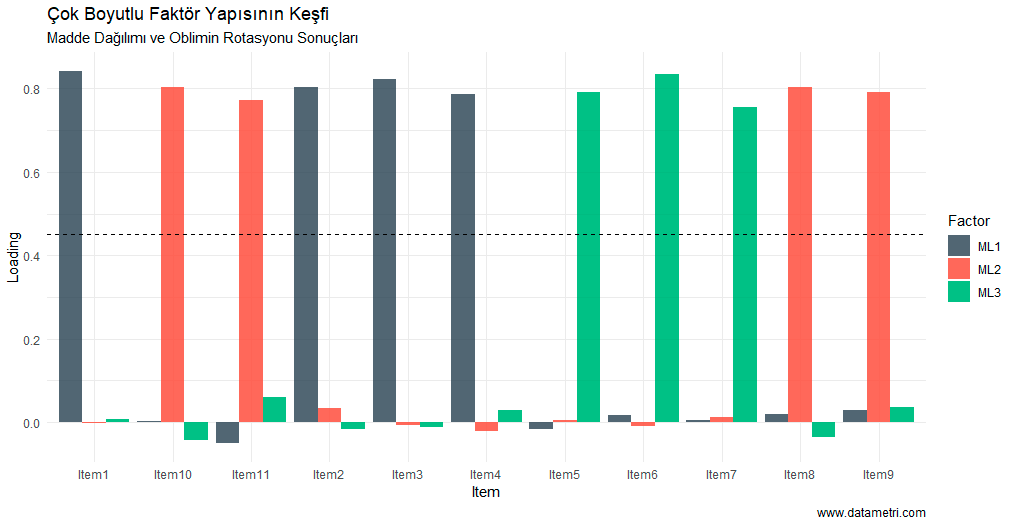
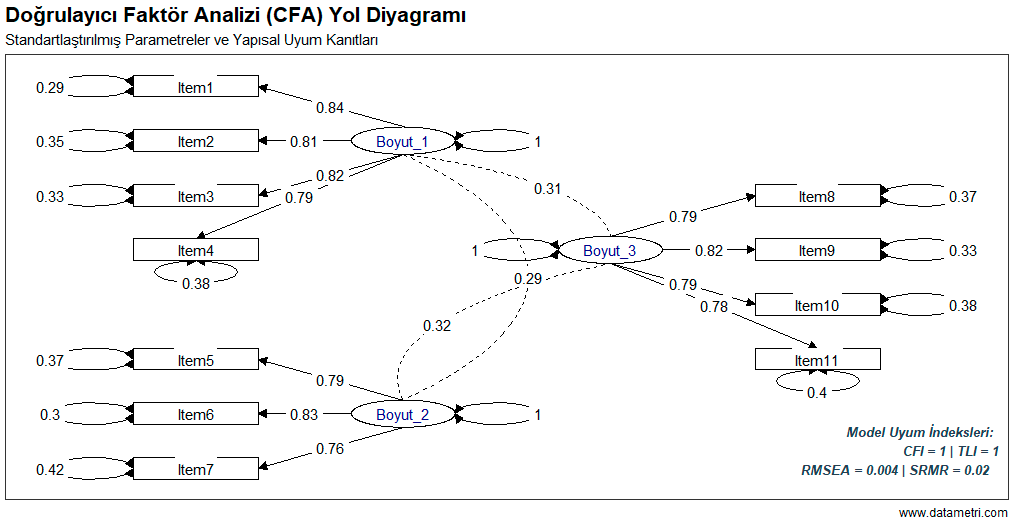
- Ölçeğimdeki maddeler tek bir kavramı (unidimensionality) ölçmede ne kadar uyumlu çalışıyor?
- Ölçeği kısaltmak (kısa form oluşturmak) istersek, hangi maddeleri feda etmek güvenilirlik kaybını minimize eder?
Araştırmanıza Sağlayacağı Ek Fayda
Kurumsal performans veya klinik anket sistemlerinde, katılımcıları yoran "gereksiz" veya "hatalı anlaşılan" soruların tespiti, veri toplama maliyetini düşürürken yanıt kalitesini (response quality) maksimize eder.
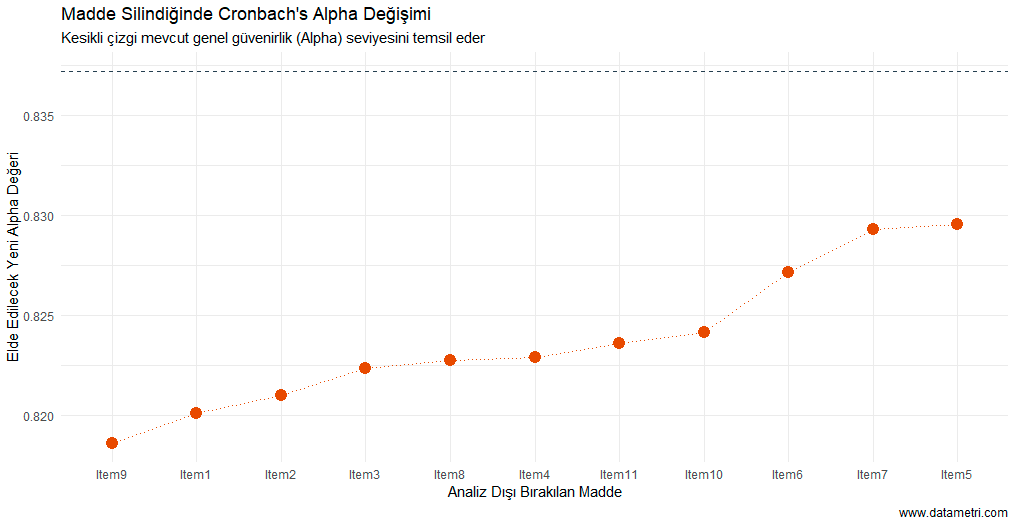
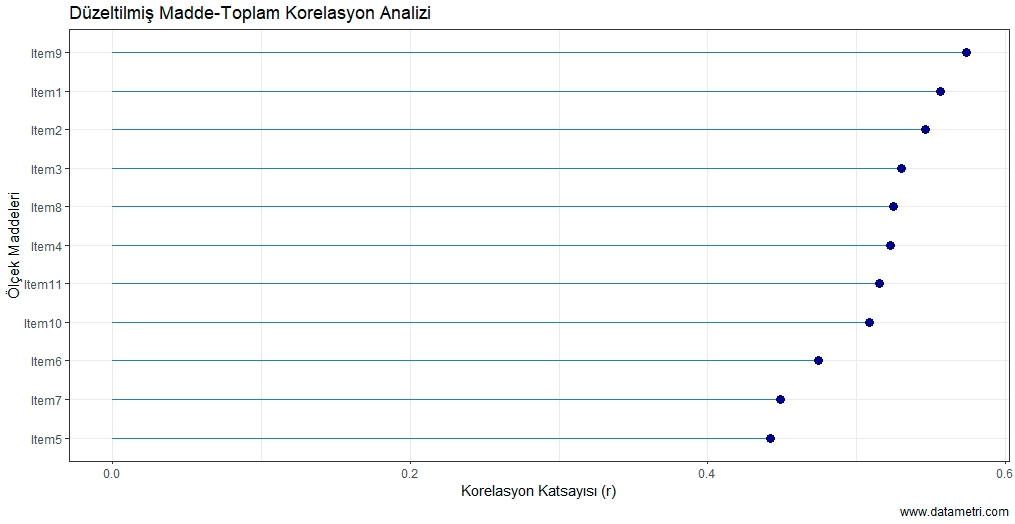
Grafikte yer alan her bir veri noktası, ilgili madde ölçekten çıkarıldığında geriye kalan maddelerin ürettiği yeni Cronbach's Alpha katsayısını gösterir. Kesikli çizgi mevcut genel güvenilirlik seviyesini temsil eder. Analiz sonucuna göre, Item9 analiz dışı bırakıldığında toplam güvenilirliğin en düşük seviyeye (0.818) gerilemesi, bu maddenin ölçeğin "çekirdek bileşeni" olduğunu kanıtlamaktadır.