Özellikle anket tabanlı pazar araştırmalarında ve sosyal bilimler projelerinde, insan faktöründen (respondent) kaynaklanan hata varyansının izole edilmesi kritik bir aşamadır. Gelişen veri toplama teknolojileri ve platform içi algoritmalar sayesinde;
- Katılımcıların bilişsel yükten kaçınmak için sorulara hep aynı yanıtı vermesi (Sıfır Varyans / Straightlining),
- Anketin okuma ve algılama biyolojik sınırlarının altında bir sürede tamamlanması (Hızlı Yanıtlayıcı / Speeder tespiti),
- Açık uçlu sorulara botlar veya dikkatsiz katılımcılar tarafından girilen anlamsız metinlerin tespiti (Gibberish / NLP Kontrolü)
gibi temel düzeydeki davranışsal anormallikler, entegre scriptler aracılığıyla veri toplama aşamasında rahatça filtrelenebilmektedir artık. Bu nedenle datametri.com olarak biz, standart yazılımların tespit edemediği, çok daha derin ve istatistiksel modelleme gerektiren deterministik tutarsızlıklara daha çok odaklanıyoruz.
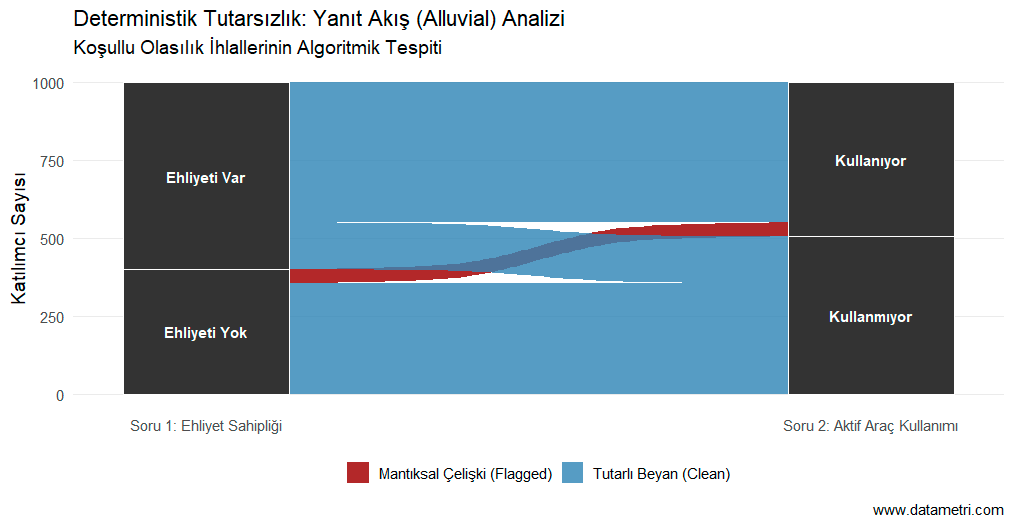
1. Deterministik Tutarsızlık ve Algoritmik Çapraz Doğrulama (Logical Consistency Checks)
"Katılımcılarınızın Mantıksal Bütünlüğünü, Akışı Algoritmalarla Test Ediyoruz"Standart platformların gözden kaçırdığı en büyük risk, katılımcının birbiriyle mantıksal olarak ilişkili veya birbirini dışlayan (mutually exclusive) sorulara verdiği koşullu çelişkilerdir. Kurduğumuz deterministik algoritmalar ve koşullu olasılık matrisleri ile veri seti içerisindeki mantıksal kırılmalar saptanarak, anketin genel geçerliliği puanlanır ve güvenilmez gözlemler izole edilir.
- Katılımcılar araştırma kurgusunu gerçekten anlayarak mı yanıtlıyor, yoksa soruları okumadan stratejik mi ilerliyor?
- Veri setimde, genel analiz sonuçlarını manipüle edecek düzeyde içsel çelişkiye sahip ne kadar katılımcı var?
Pazar dinamiklerini okurken veya yeni bir ürün konumlandırırken, birbiriyle çelişen tüketici beyanları üzerinden alınan stratejik kararların maliyeti çok yüksektir. Bu analiz, içgörülerinizi (insights) yalnızca kendi içinde %100 mantıksal tutarlılığa sahip, doğrulanmış "gerçek" hedef kitle verisi üzerine inşa etmenizi sağlar; araştırma bütçenizin getirisini (ROI) korur.