01
Yönetim Kurulları İçin Stratejik Karar Alma ve Stokastik Vizyon (C-Level Data Literacy)
▼
Üst düzey yöneticilerin (CEO, CMO, CFO) teknik algoritmaları yazması beklenmez; ancak kendilerine sunulan analitik modellerin epistemolojik sınırlarını ve varyans düzeylerini denetleyebilmeleri stratejik bir zorunluluktur. Bu modül, karar alıcıların deterministik yanılgılardan kurtulup, riski ve belirsizliği olasılıksal (probabilistic) bir çerçevede yönetmelerini hedefler.
Eğitim Müfredatı ve Akademik Kazanımlar:
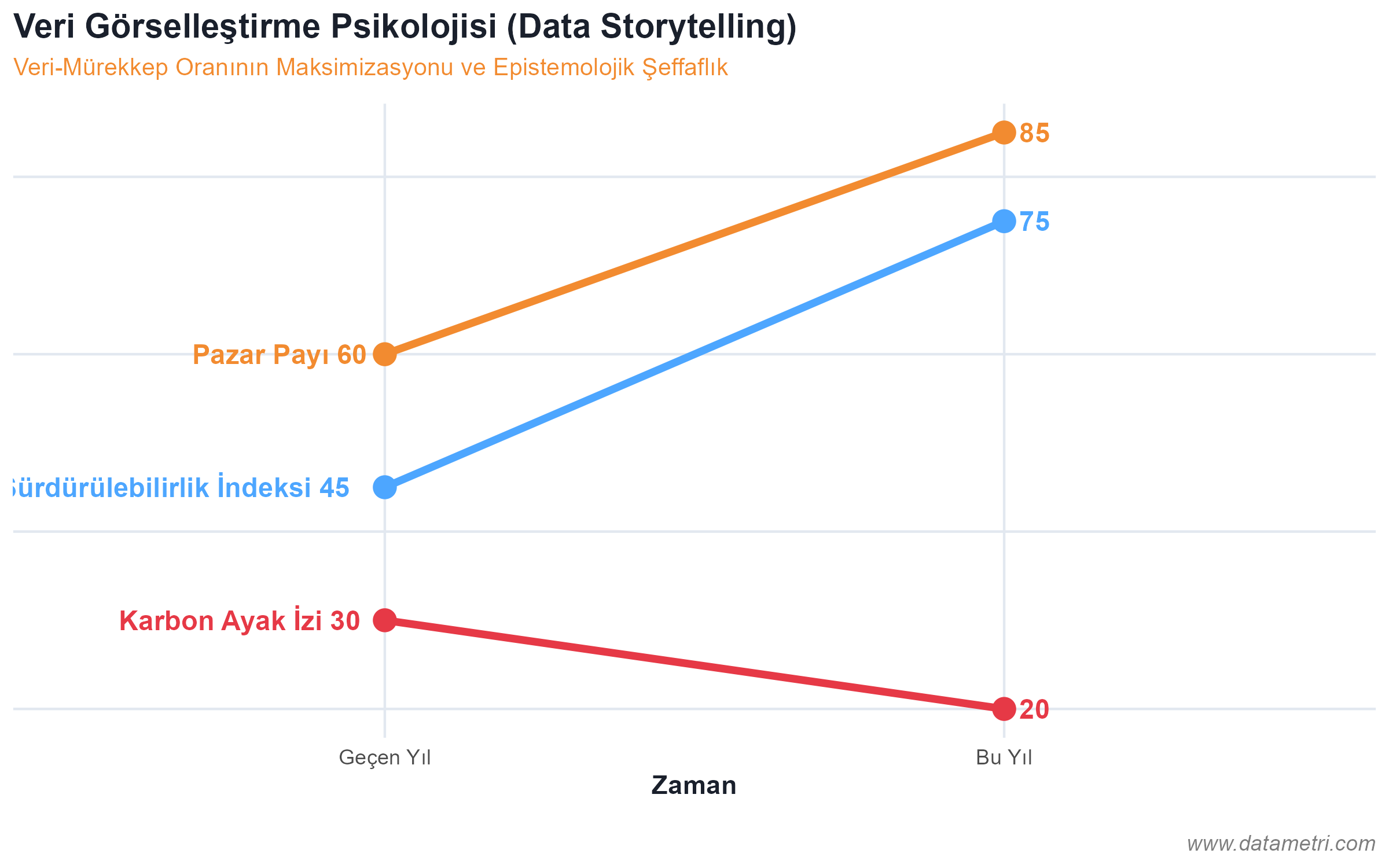
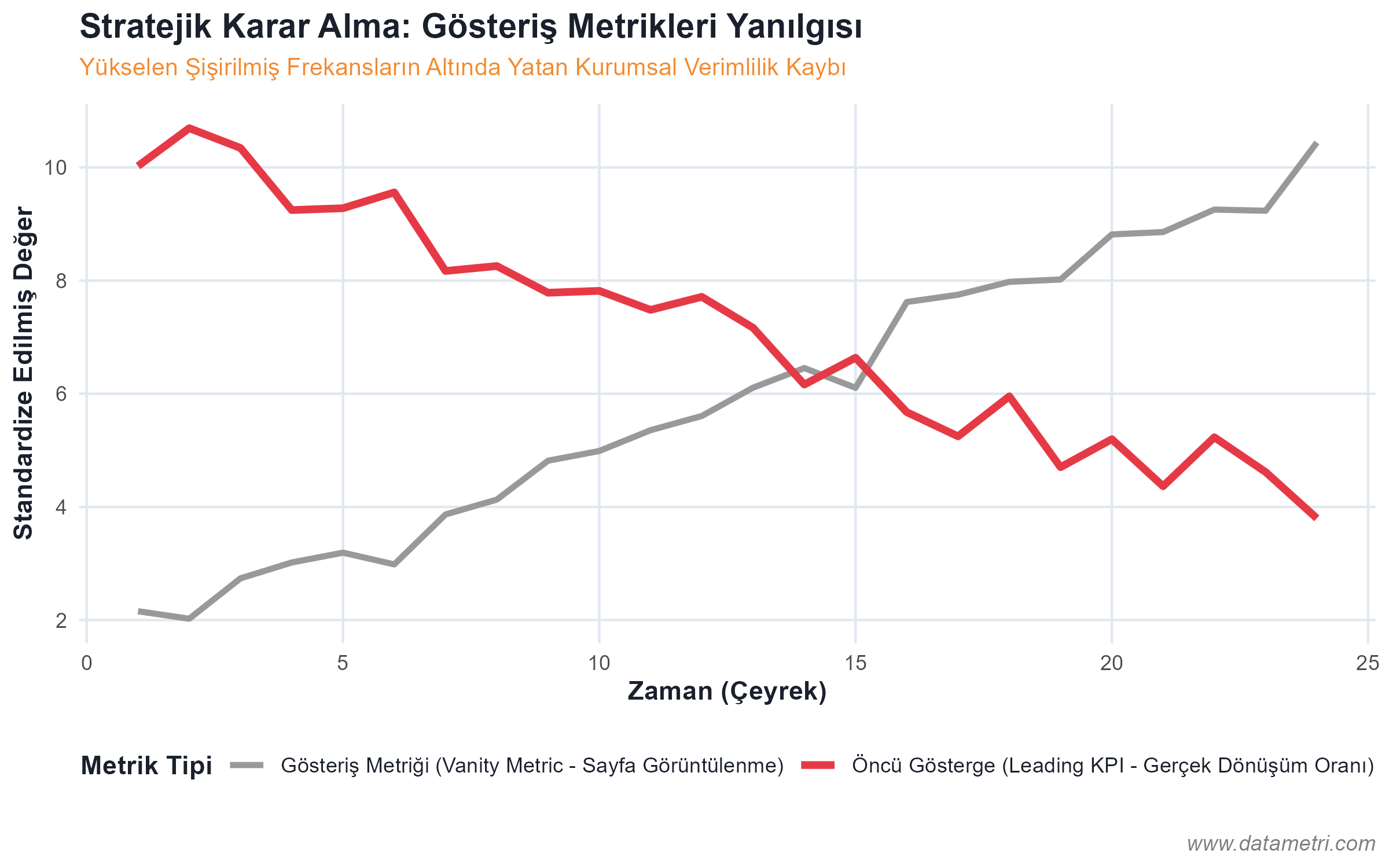
- Sahte Metriklerin (Spurious Metrics) İzolasyonu: Sayfa görüntülenmeleri gibi tahmin edici geçerliliği (Predictive Validity) olmayan gösteriş metriklerinin (Vanity Metrics) reddedilmesi. Bunların yerine, nedensel aksiyon üretebilen "Öncü Göstergelerin (Leading Indicators)" sisteme entegrasyonu.
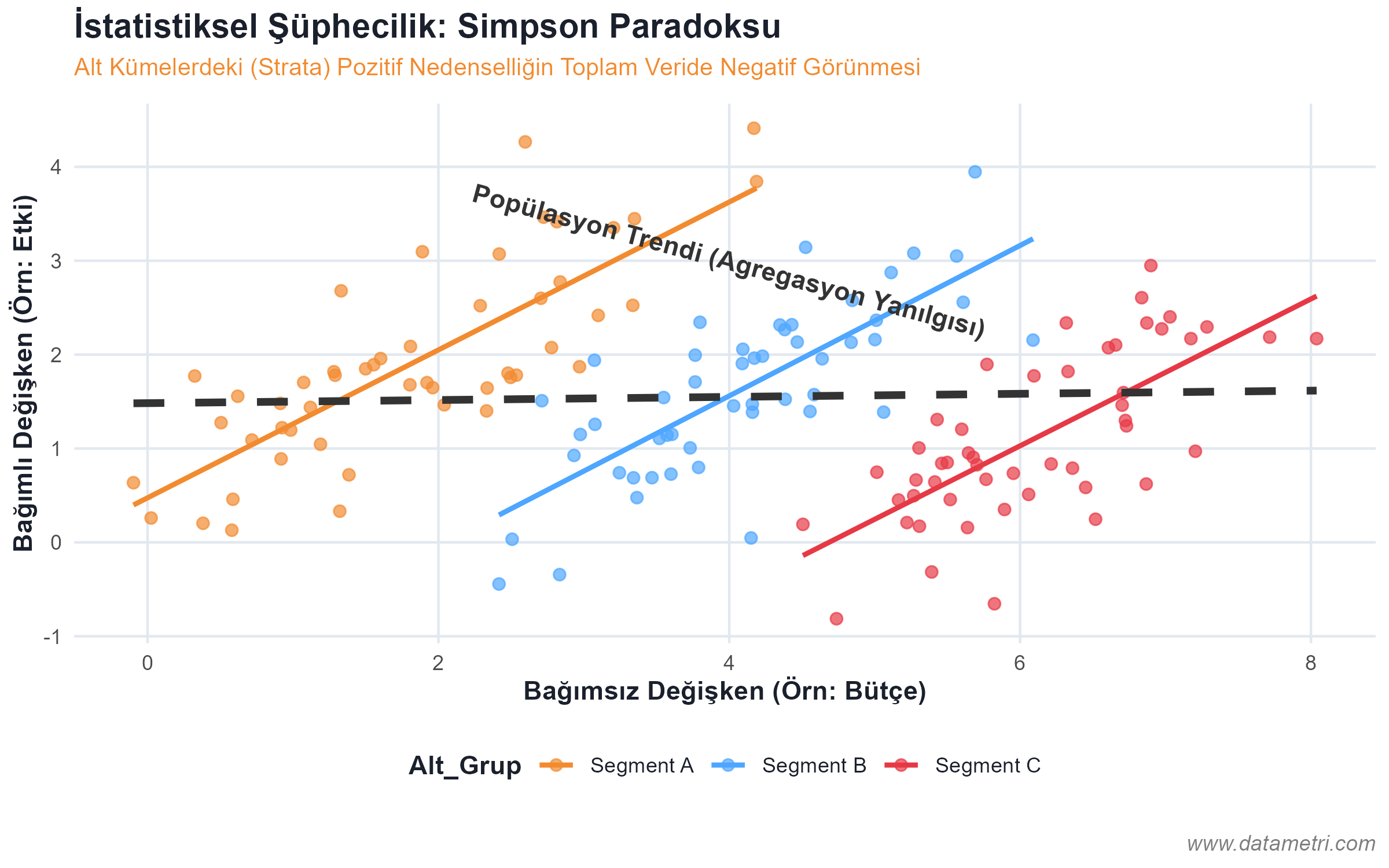
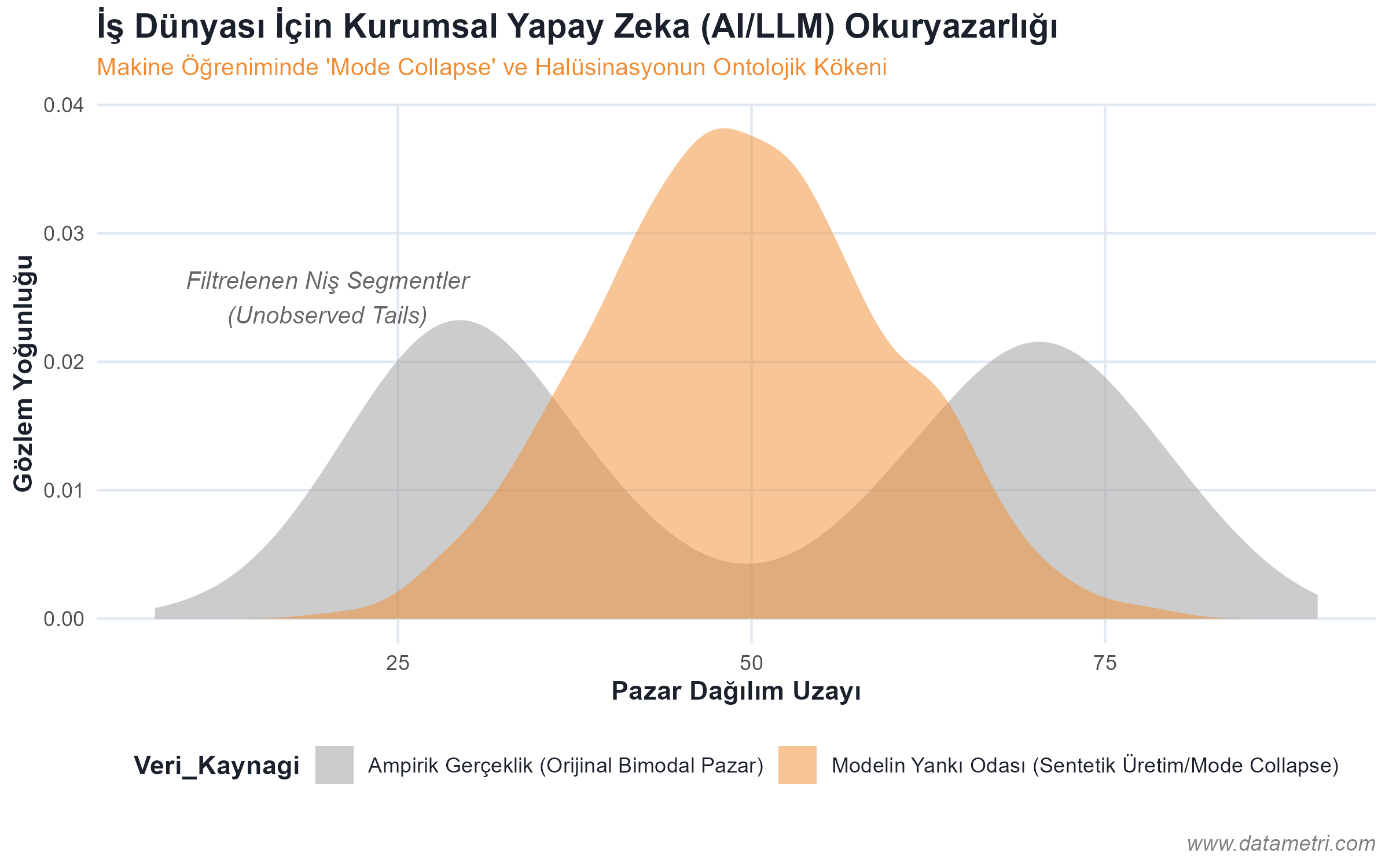
- Nedensellik ve Korelasyon Asimetrisi: Eşzamanlı hareket eden iki değişken arasındaki sahte ilişkilerin (Spurious Correlation) tespiti; dışsal karıştırıcıların (Exogenous Confounders) modelden arındırılmasını veri ekiplerinden talep etme yetkinliği.
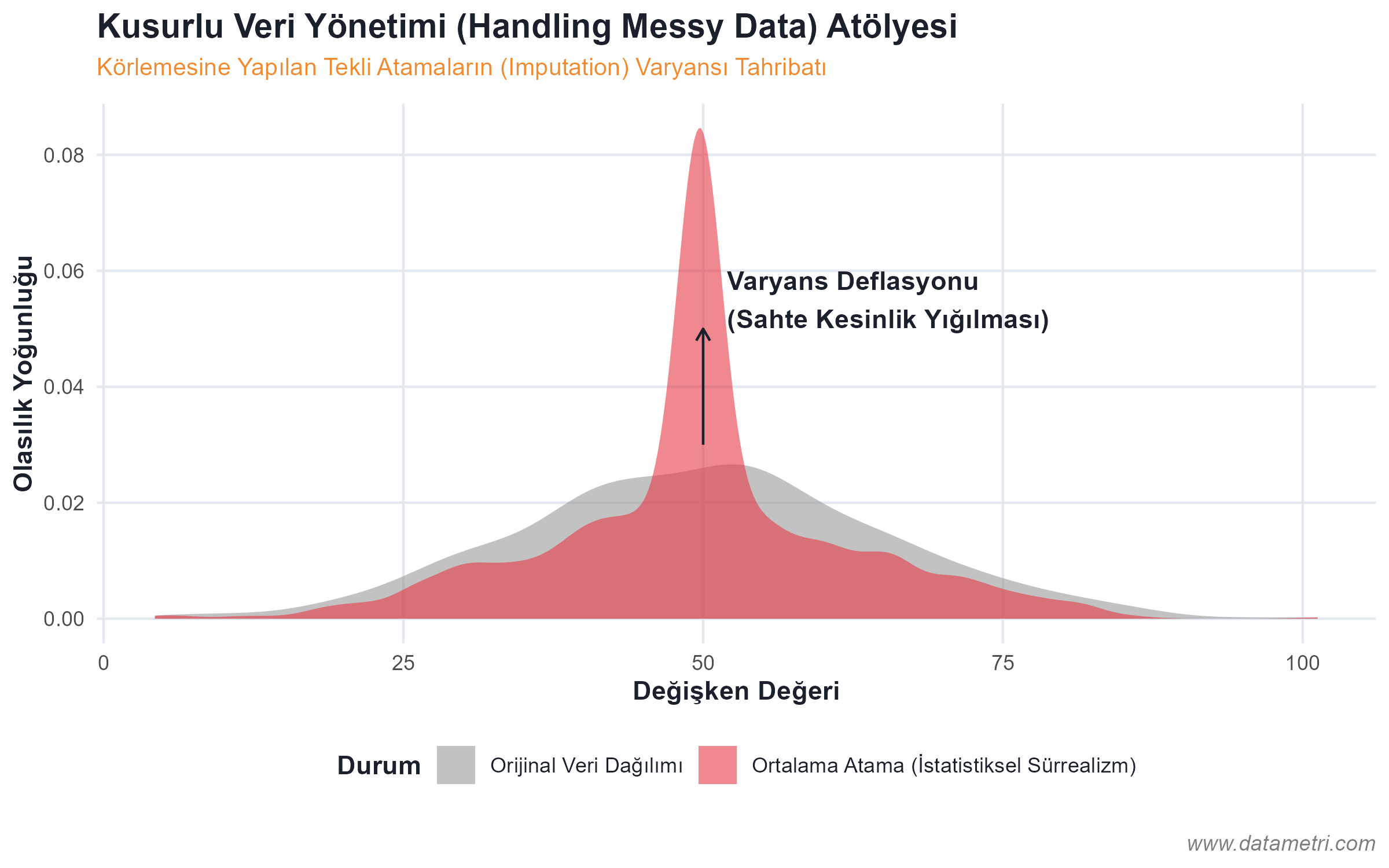
- Güven Aralıkları (Confidence Intervals) ve Varyans Tahmini: Raporlardaki nokta tahminlerine (Point Estimates) mutlak doğrular olarak yaklaşmak yerine, istatistiksel hata paylarını (Standard Error) karar mekanizmasına dahil etme pratiği.
caption = 'www.datametri.com'
Bu program, yönetim kurullarını rapor tüketicisi (passive consumer) konumundan çıkarıp, verinin metodolojik geçerliliğini denetleyen (auditing) ve stratejiyi ampirik kanıtlar üzerine inşa eden bir otoriteye dönüştürür.