01
Strategic Decision Making and Stochastic Vision for Boards of Directors (C-Level Data Literacy)
▼
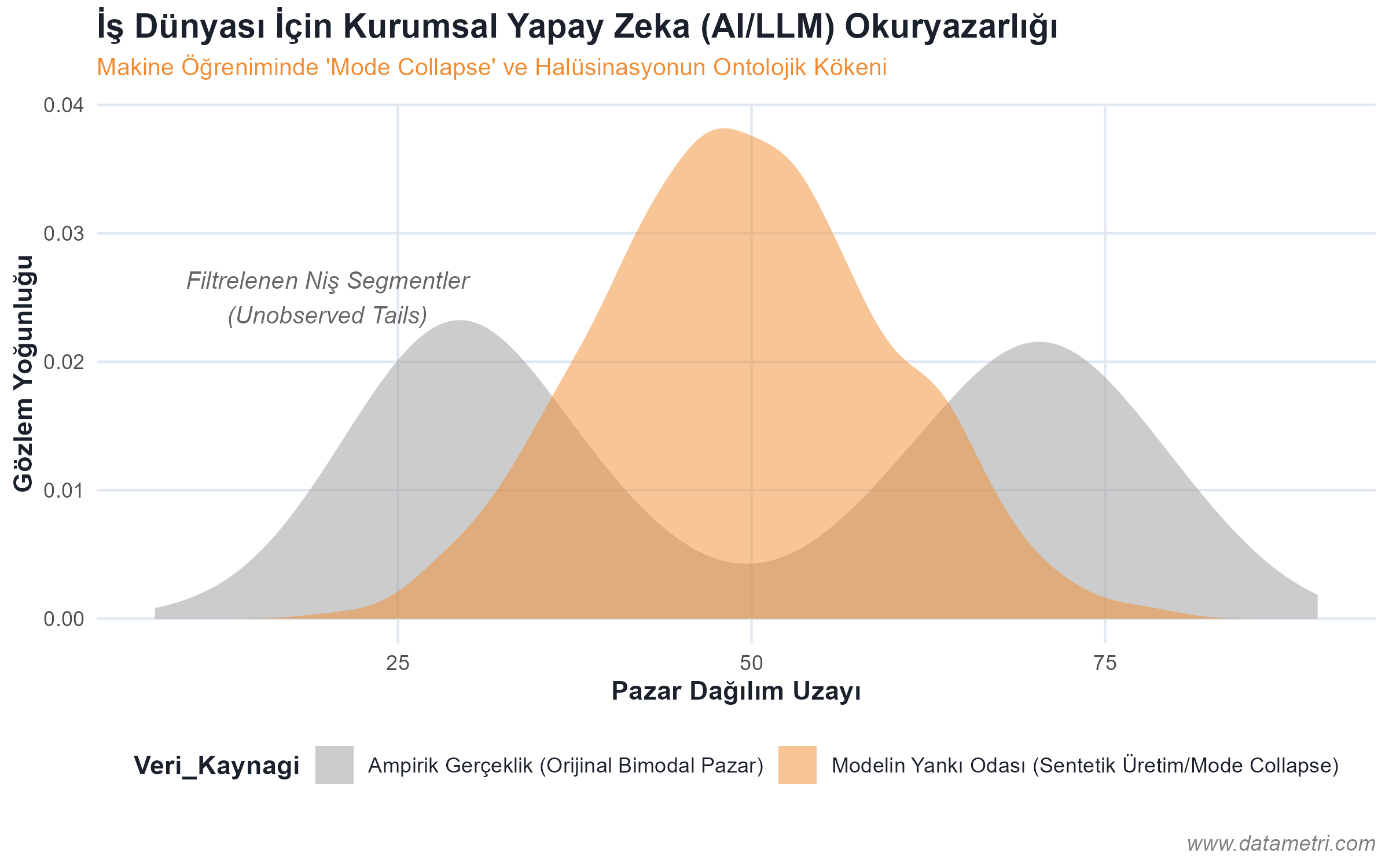
Top-level executives (CEO, CMO, CFO) are not expected to write technical algorithms; however, their ability to audit the epistemological limits and variance levels of the analytical models presented to them is a strategic necessity. This module aims for decision-makers to break free from deterministic fallacies and manage risk and uncertainty within a probabilistic framework.
Training Curriculum and Academic Outcomes:
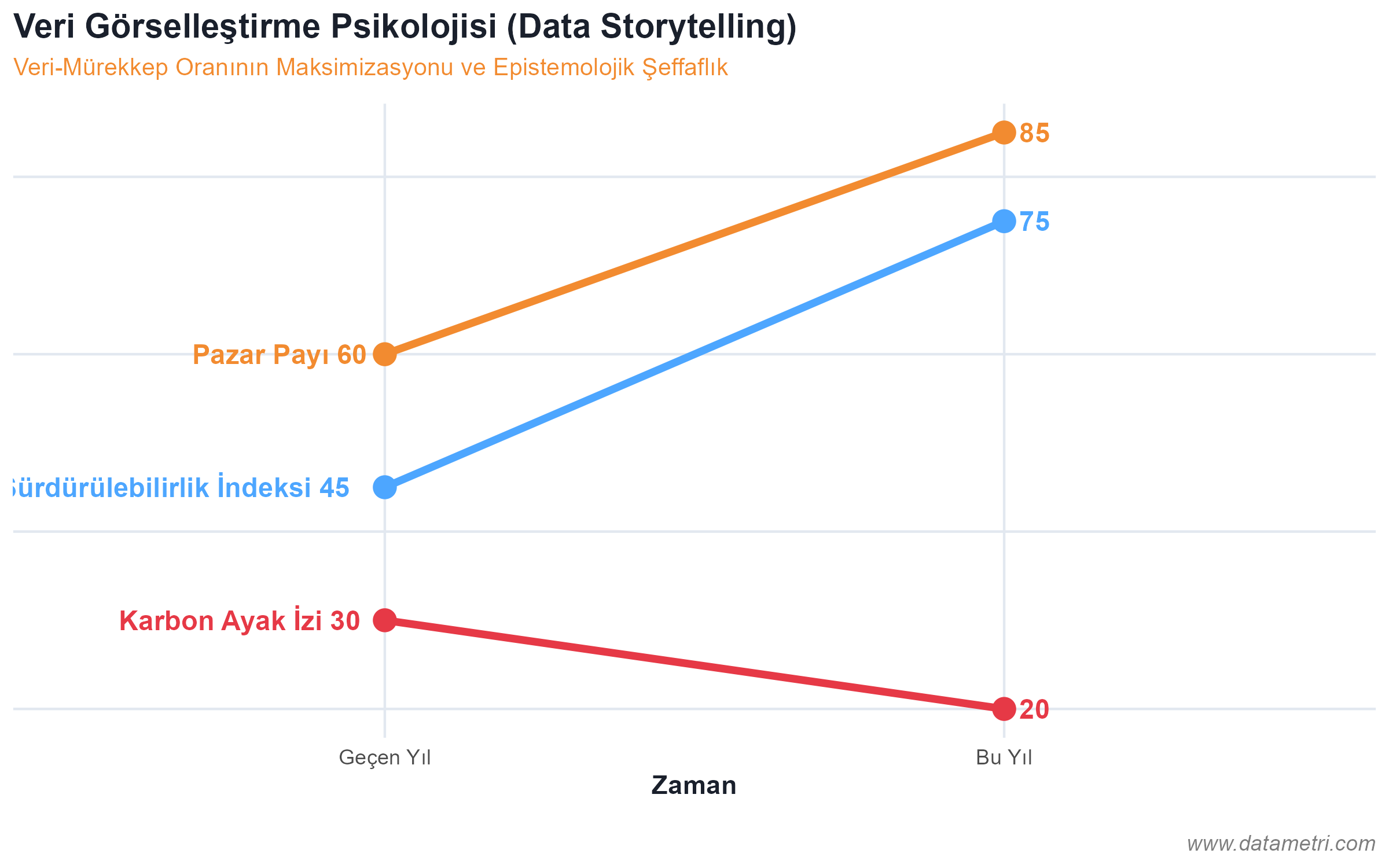
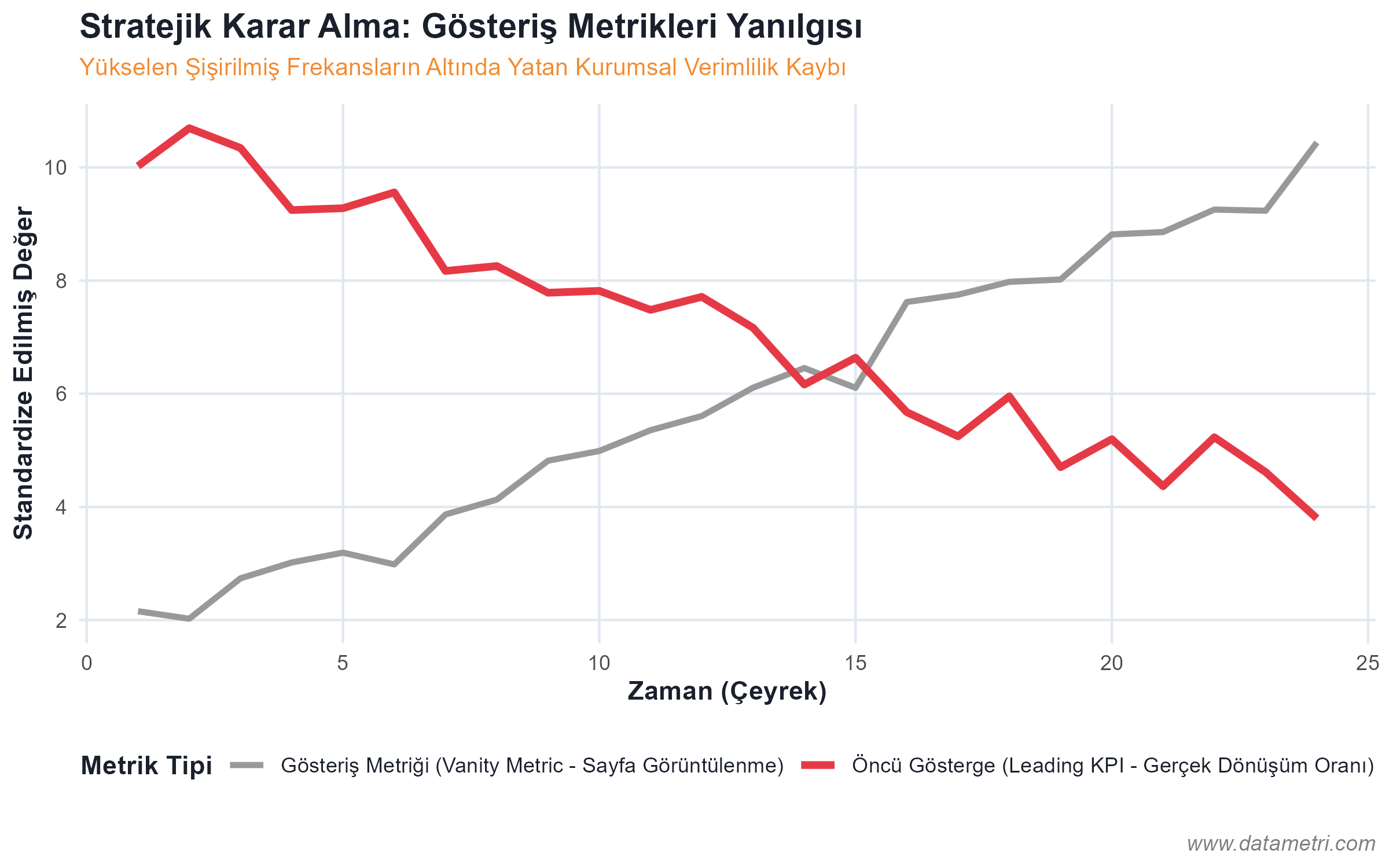
- Isolation of Spurious Metrics: Rejecting Vanity Metrics that have no Predictive Validity, such as page views. The integration of "Leading Indicators" capable of generating causal action into the system instead.
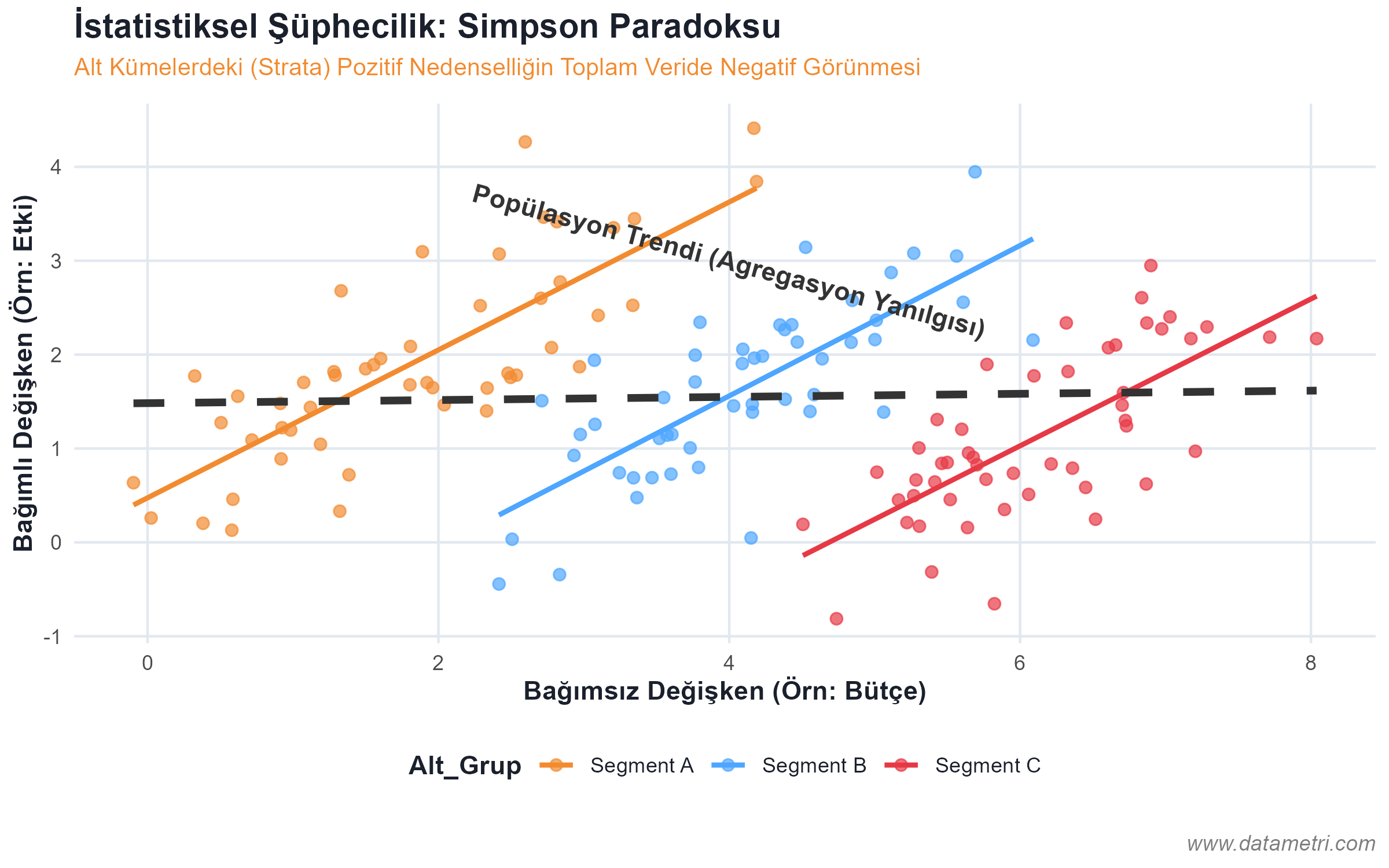
- Causality and Correlation Asymmetry: Detecting spurious correlations between two variables moving simultaneously; the competency to demand data teams to purge Exogenous Confounders from the model.
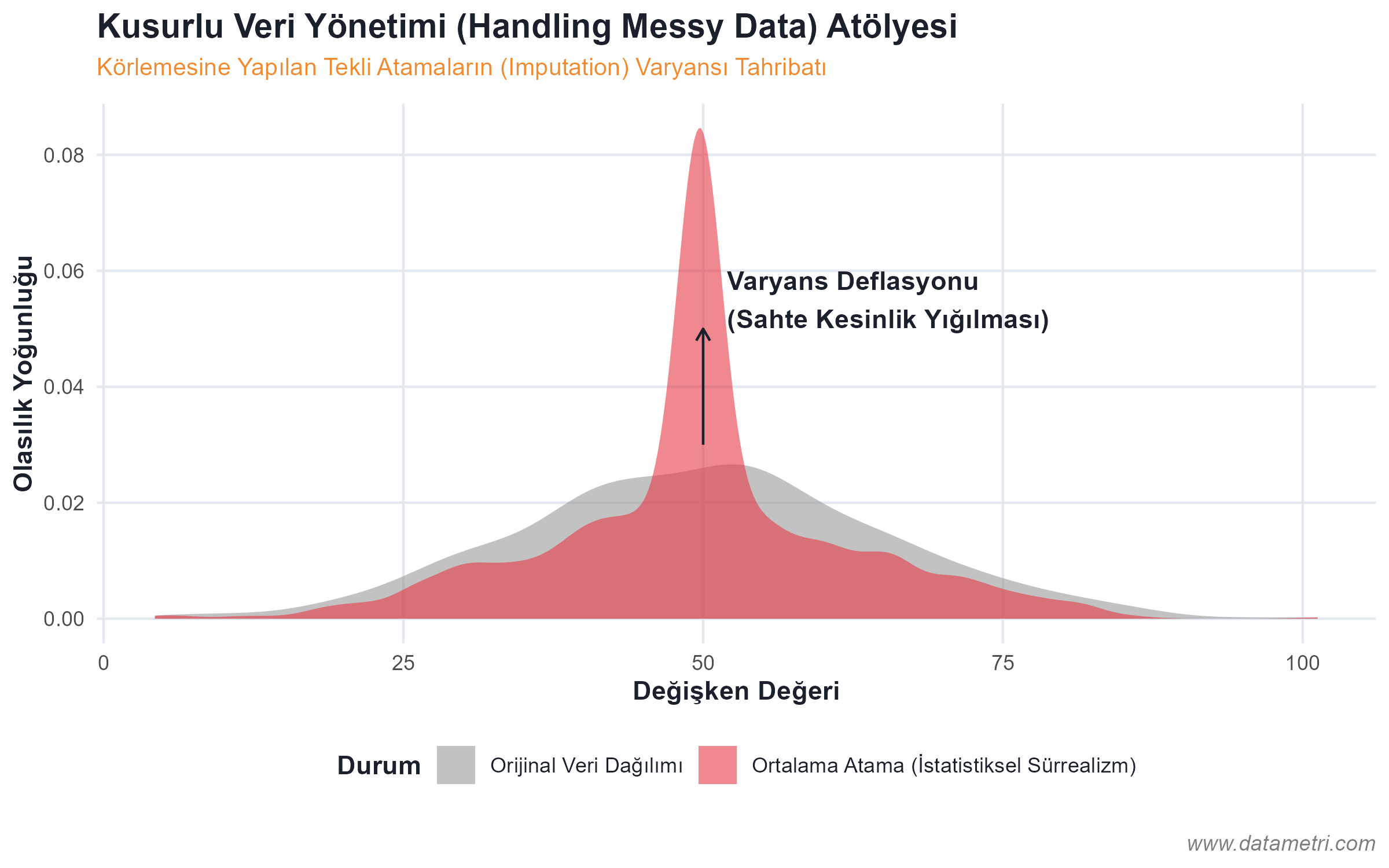
- Confidence Intervals and Variance Estimation: The practice of incorporating statistical margins of error (Standard Error) into the decision mechanism, instead of treating Point Estimates in reports as absolute truths.
caption = 'www.datametri.com'
This program elevates boards of directors from the position of a passive consumer of reports and transforms them into an authority that audits the methodological validity of data and builds strategy on empirical evidence.