01
Domain-Specific Ontology and RAG (Retrieval-Augmented Generation) Architecture
▼
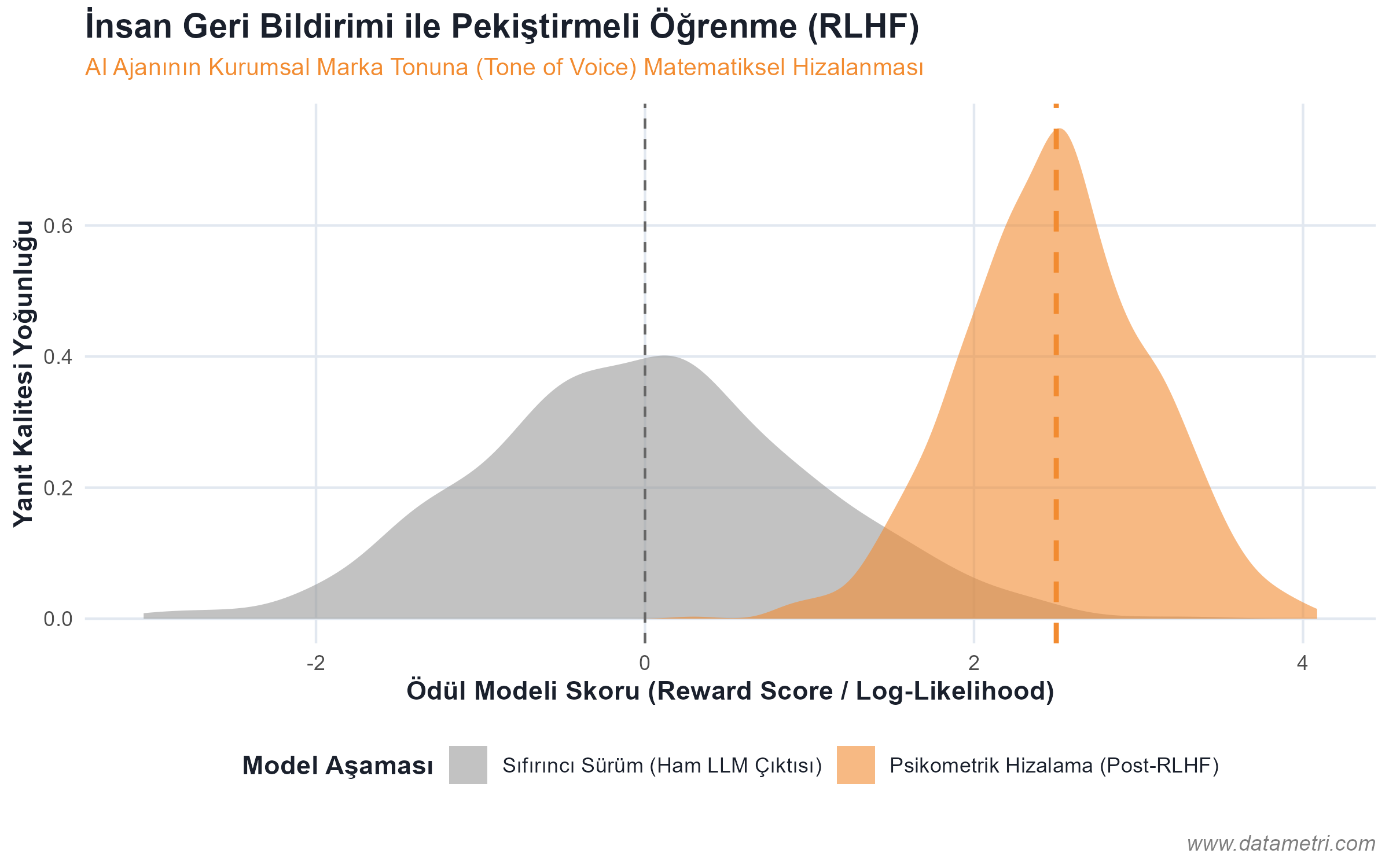
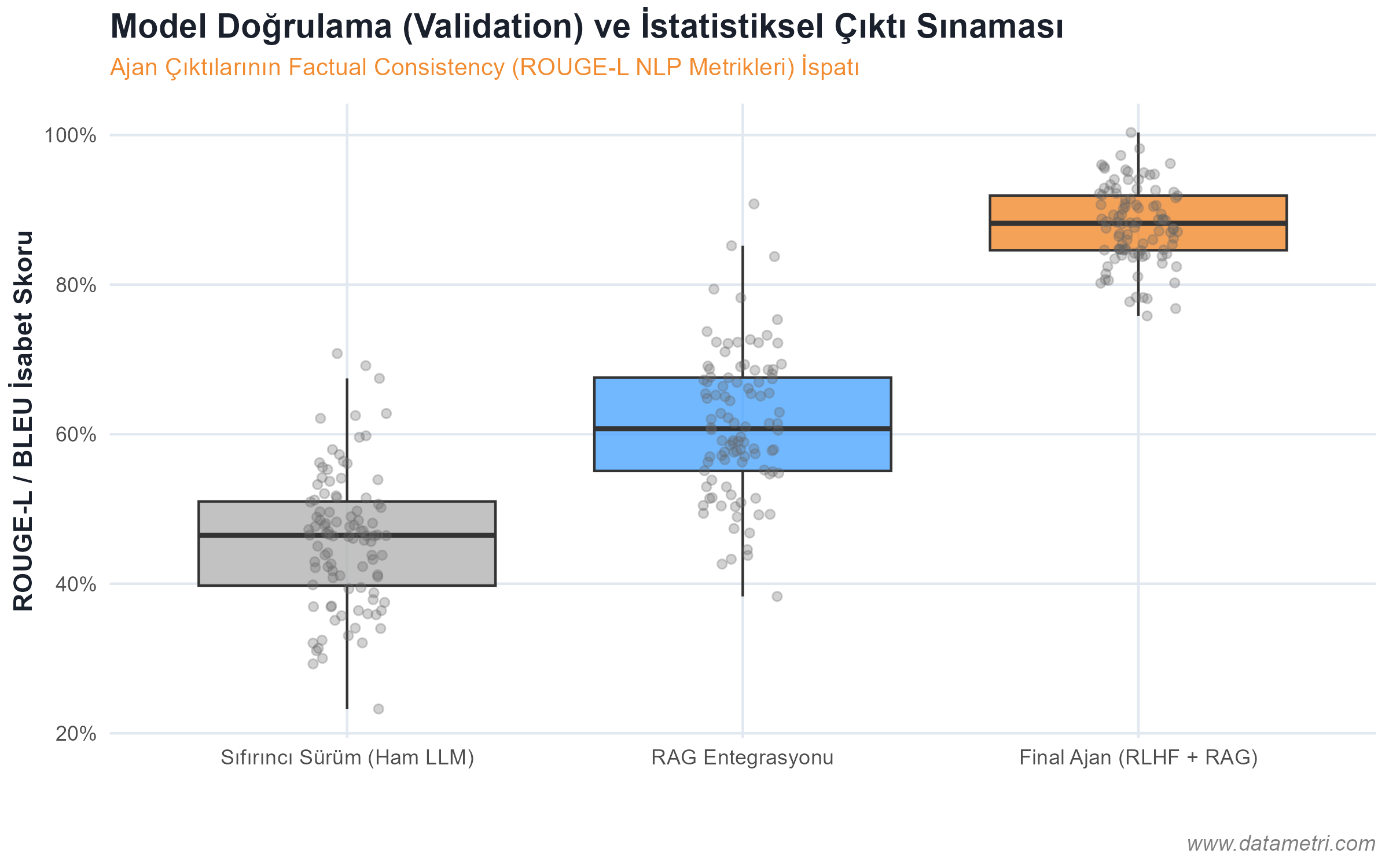
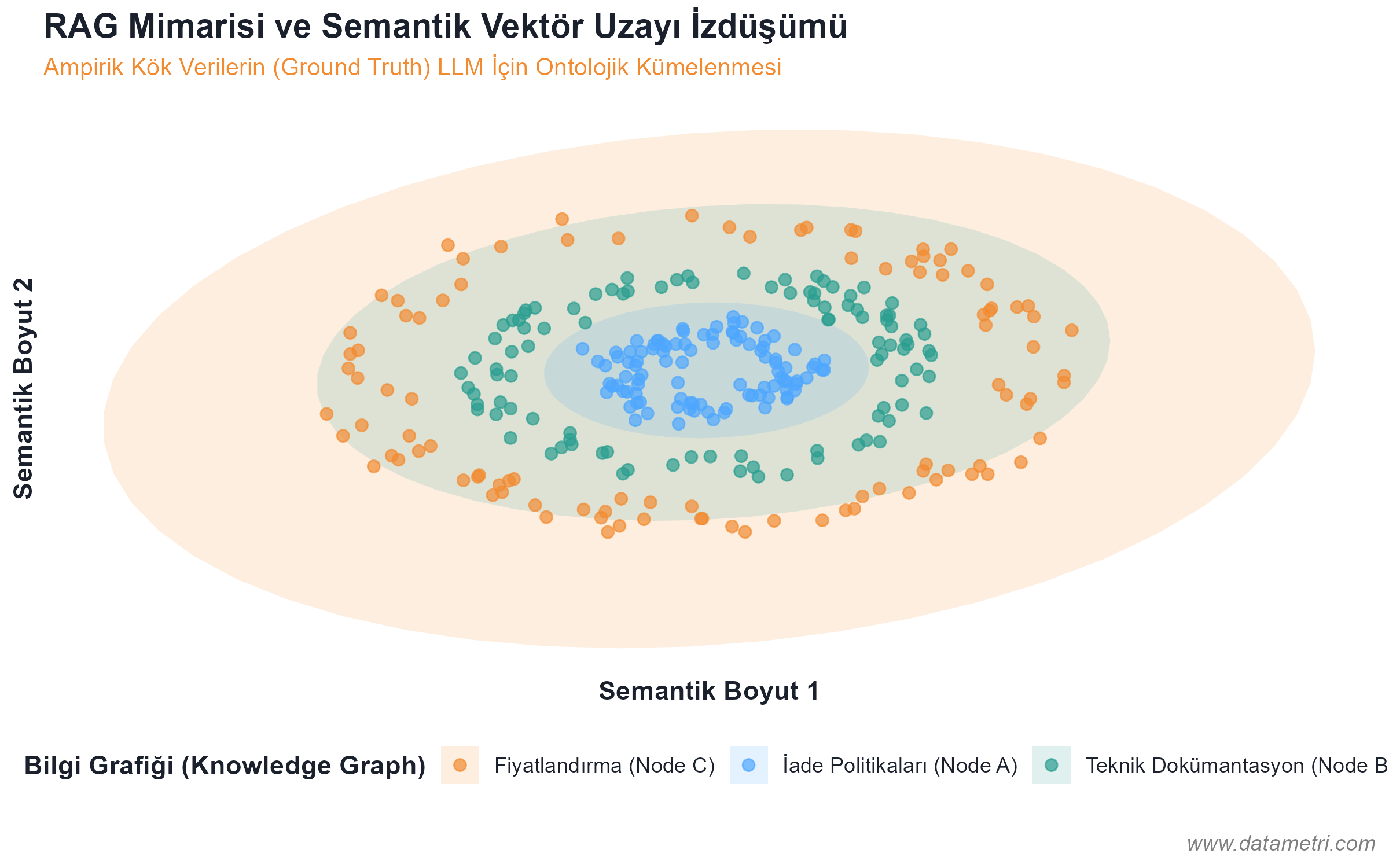
For an artificial intelligence agent to correctly interpret the specific (domain-specific) rules of your institution, the data must be presented to the model not as a "whole text"; but isolated in a mathematical vector space. This architecture prevents the LLM from confusing its pre-trained general internet knowledge with corporate data.
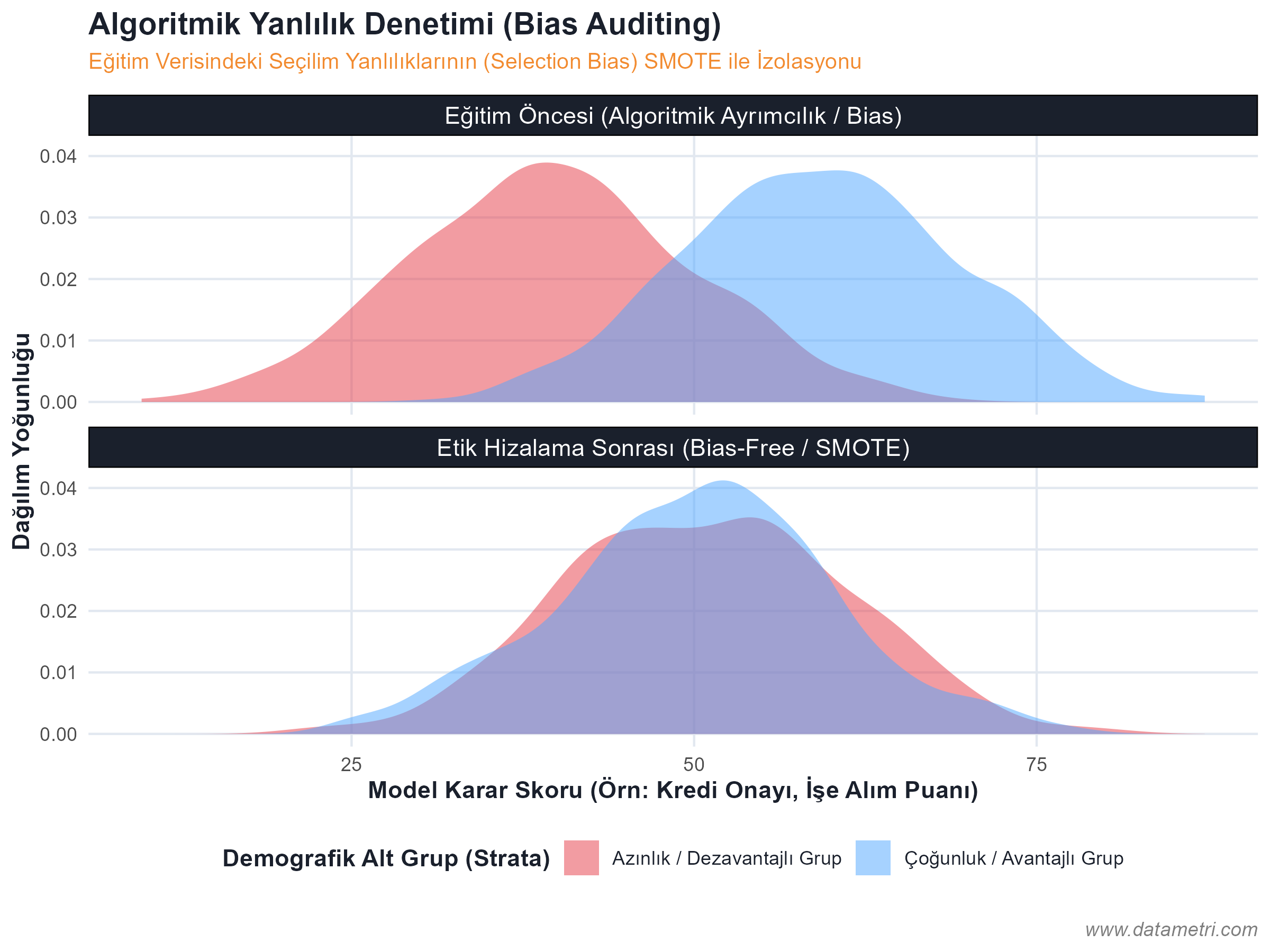
Isolated Biases and Methodological Countermeasures
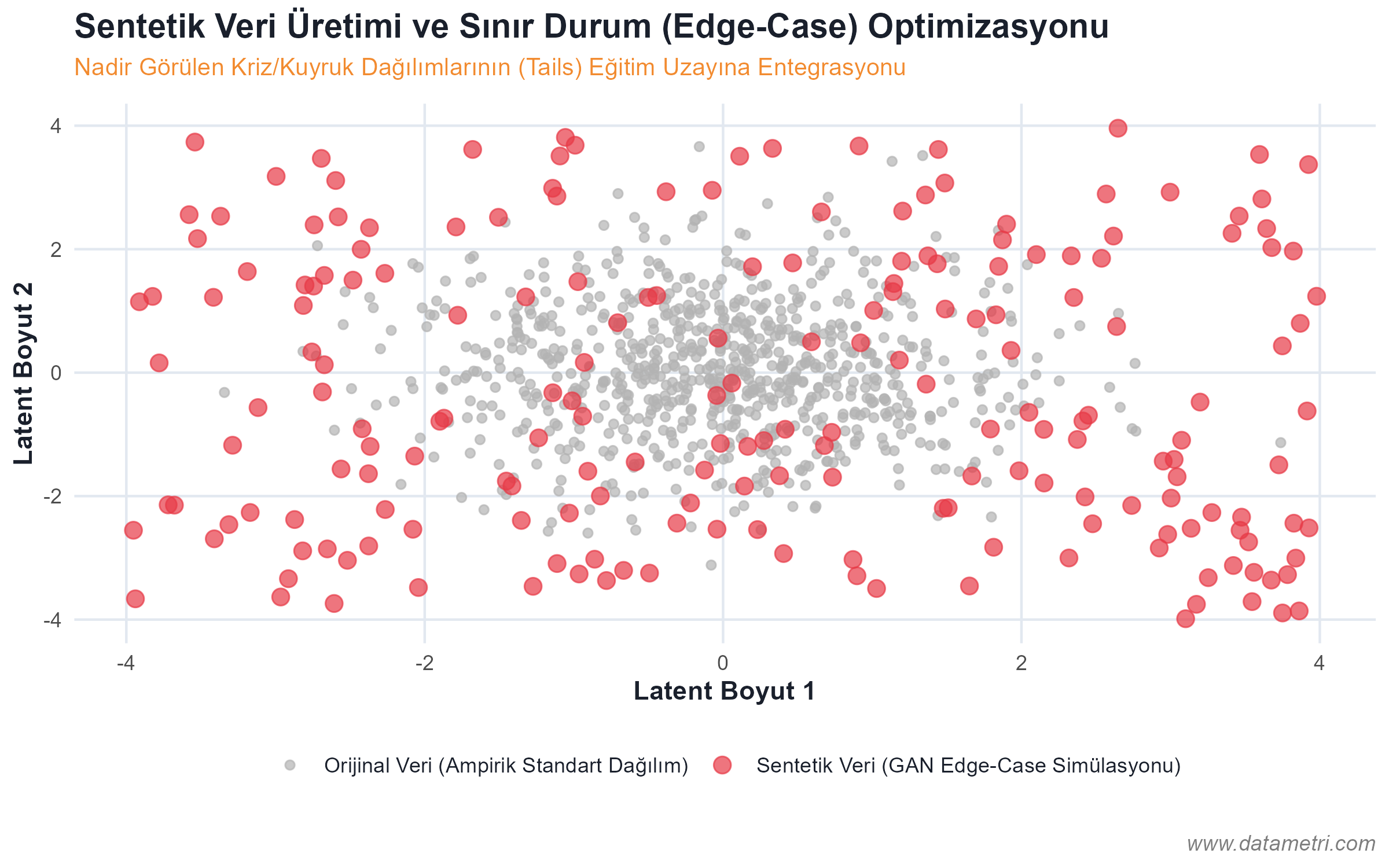
- The Ontological Origin of Hallucination: To prevent the model from generating information that "doesn't actually exist," we separate documents into logical nodes (Semantic Chunking) and place them in Vector Databases. Thus, the model is forced to draw the answer not from its memory, but directly from the pointed "Ground Truth".
- Knowledge Graphs: By connecting the causality relationships between concepts to be integrated into the RAG architecture with a strict ontological map, we keep the model's reasoning ability algorithmically under control.
caption = 'www.datametri.com'
It ensures that your AI agent ceases to be a memory-based "black box"; and attains a statistical determinism that operates solely within the empirical boundaries of your corporate reality (Closed System).