01
Learning Measurement and Item Response Theory (IRT) Integration
▼
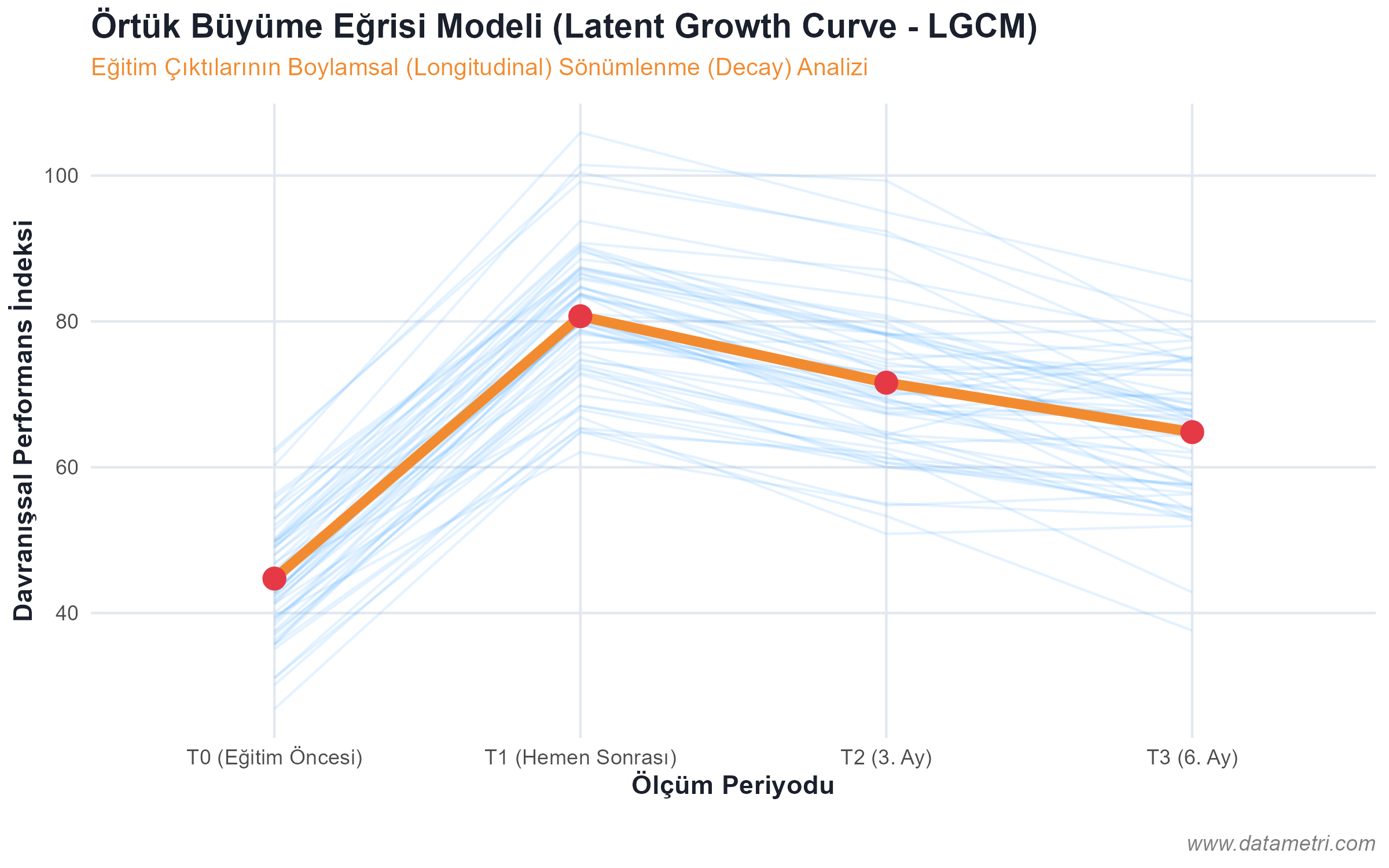
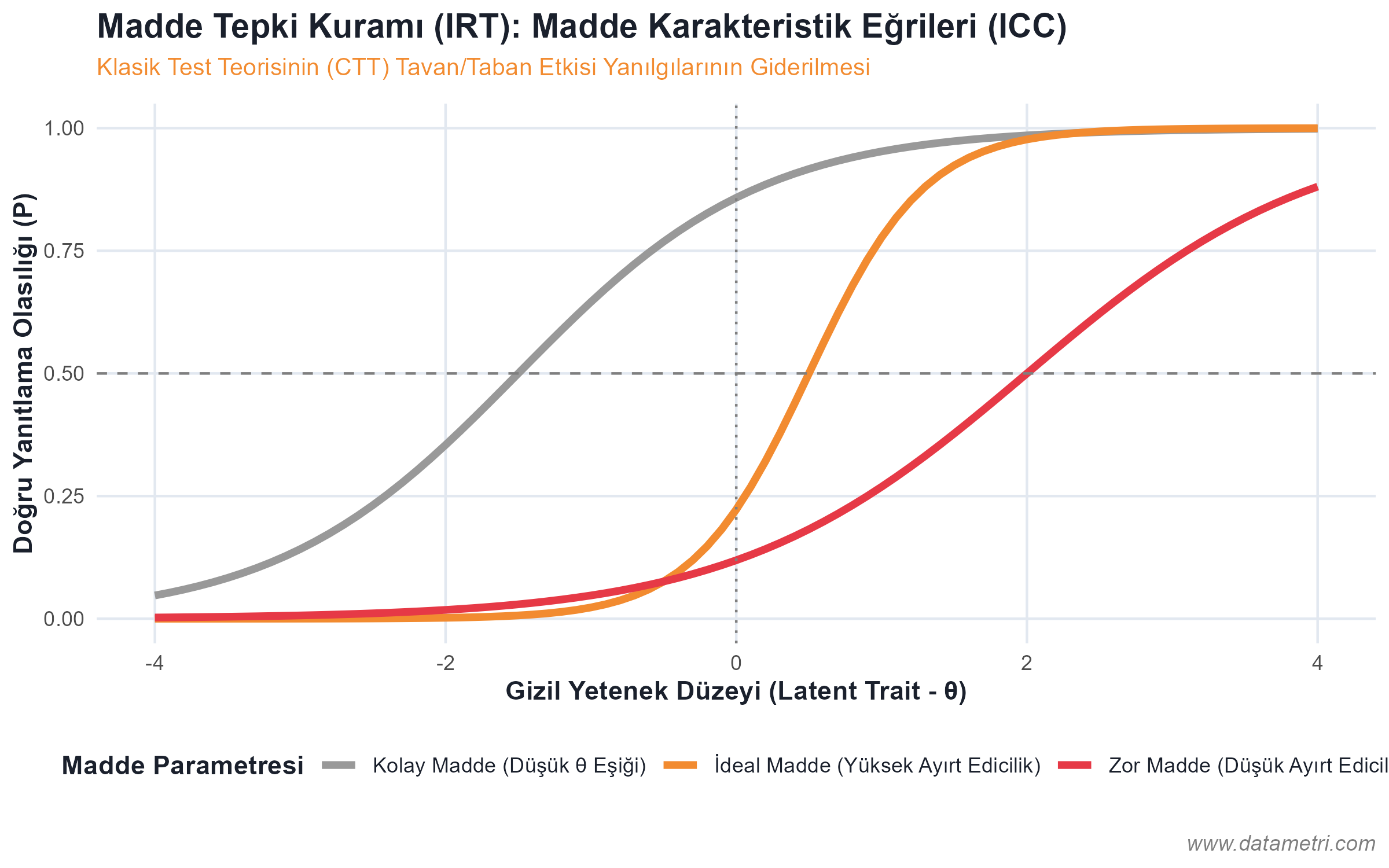
Evaluating the knowledge level of participants after training with absolute scores within the framework of Classical Test Theory (CTT) (e.g., getting 80 out of 100) is highly susceptible to measurement error. Because each question in the test has a different Item Difficulty index and Discrimination power. We ground our evaluation designs on the foundation of Item Response Theory (IRT), which centers on the test item rather than the participant.
Isolated Biases and Countermeasures
- Ceiling and Floor Effects: To prevent measurement restrictions arising from the test being too difficult or too easy, we calibrate item characteristic curves (ICC); preventing the fallacy of equating an employee who knows easy questions with an employee who knows difficult questions at the same absolute score (Test-wiseness Bias).
- Latent Trait Estimation ($\theta$): Not just the participant's number of correct answers, but their true Latent Ability is calculated with logit/probit models based on the parameters of the questions.
caption = 'www.datametri.com'
Our goal is to ensure that training departments prove that the test can measure participant competency with a zero margin of error (Item Information Function), rather than relying on superficial frequencies like "Our exam was easy, our pass rate is 90%."