01
Association Rules Analysis
▼
"Model Hidden Associations Between Products on a Statistical Scale"
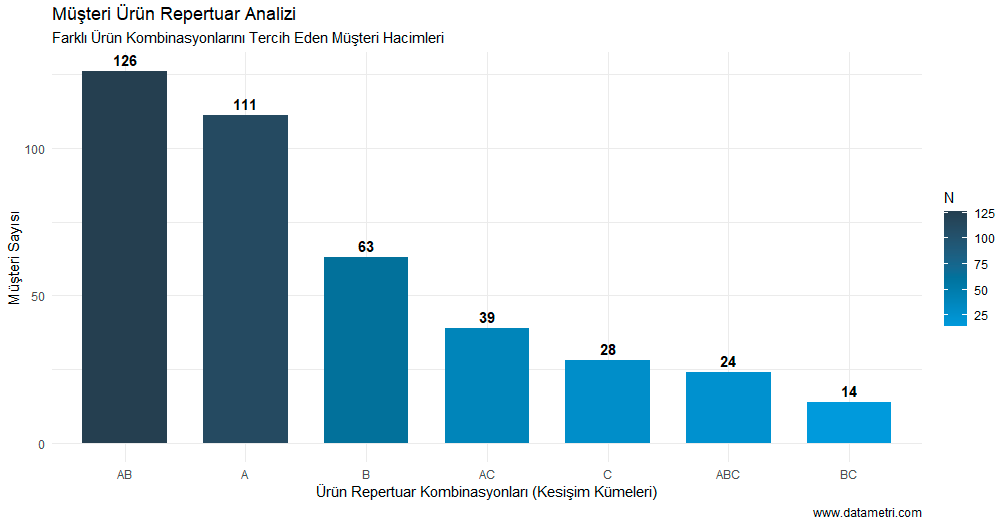
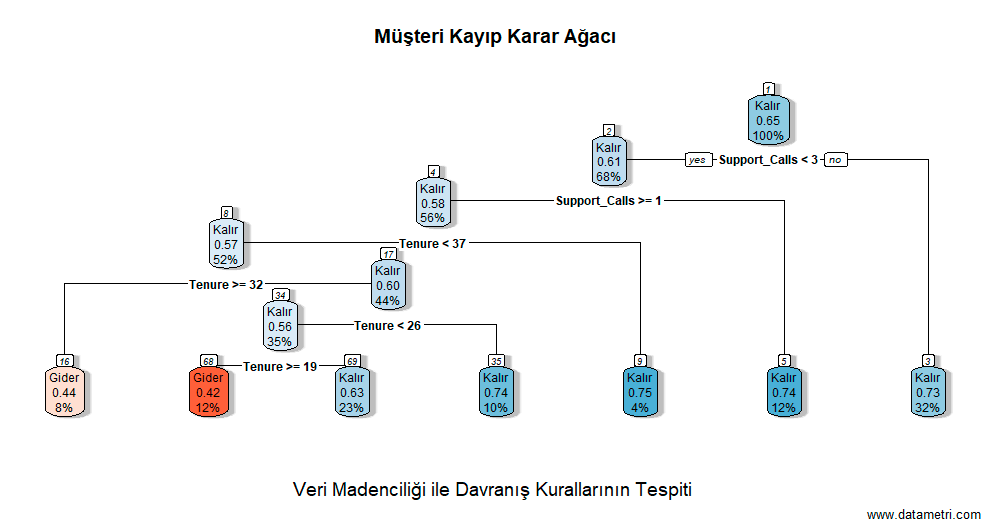
Based on the Apriori Algorithm, this analysis simultaneously scans product combinations within market basket data to reveal non-random purchasing associations. Supported by parametric calculations (Support, Confidence, Lift), this model provides a scientific foundation for cross-sell and campaign setups.
Which Questions Does This Analysis Answer?
- Which complementary product is mathematically most likely to be added to the basket by a customer purchasing a specific core product?
- Among the relationships between product combinations, which are coincidental (spurious), and which represent a strong behavioral pattern (Lift > 1)?
What Could Be the Added Value to Your Business?
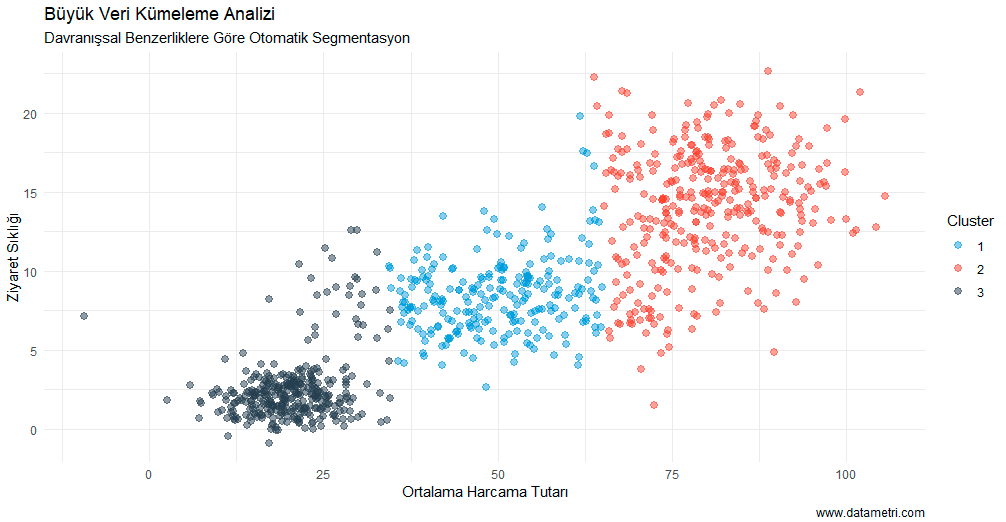
- Inventory and Shelf Optimization: Minimizes sales losses by enabling simultaneous stock management of products consumed together with a high correlation (complementary goods).
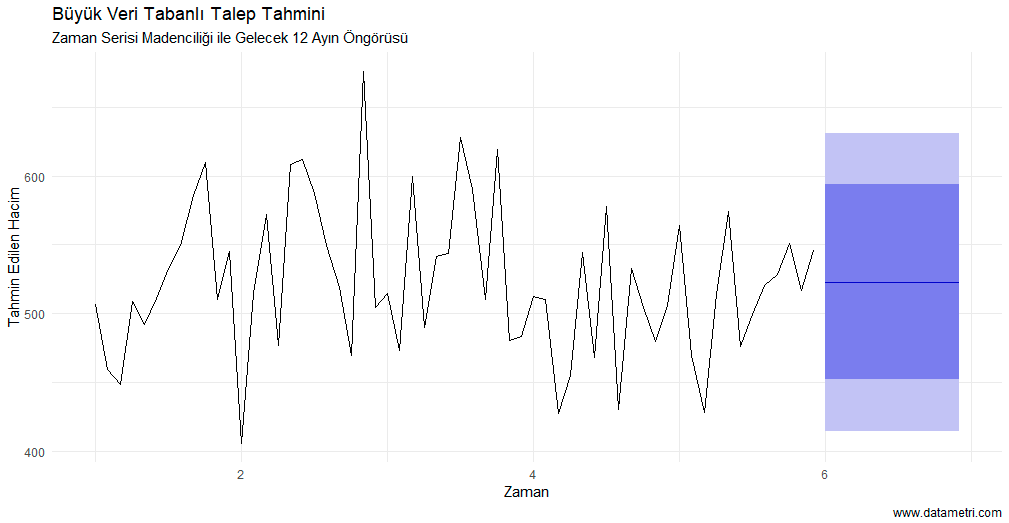
- Marginal Campaign Strategy: Instead of offering discounts on products already purchased together by the consumer (high correlation), it supports protecting your profit margin by bundling "triggering" products with those having low correlation but high potential.
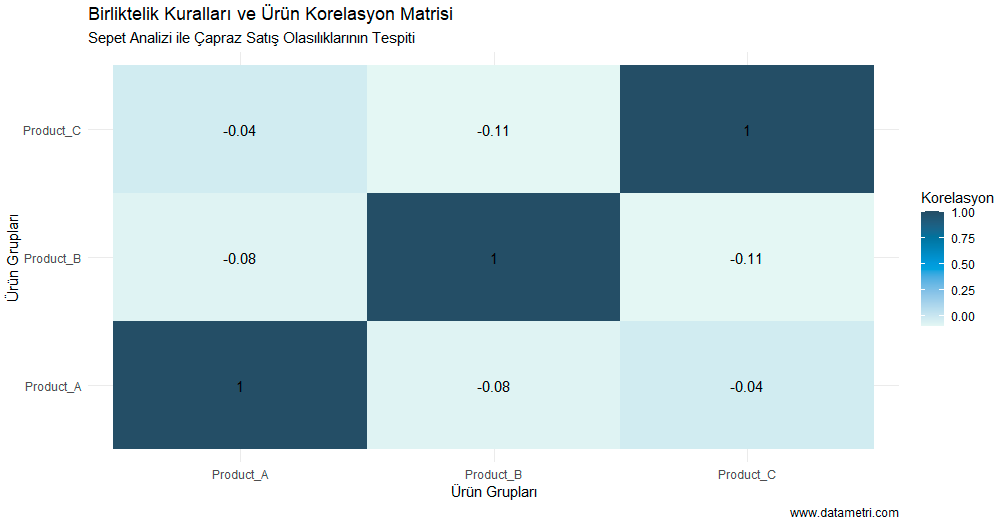
The color intensity and Pearson coefficients in the correlation heatmap quantitatively represent the strength of the linear relationship between products. As the coefficient approaches +1.00 (dark blue areas), it empirically proves that the sale of one product statistically triggers the other at a significant level.