01
Etki Alanına Özgü Ontoloji ve RAG (Retrieval-Augmented Generation) Mimarisi
▼
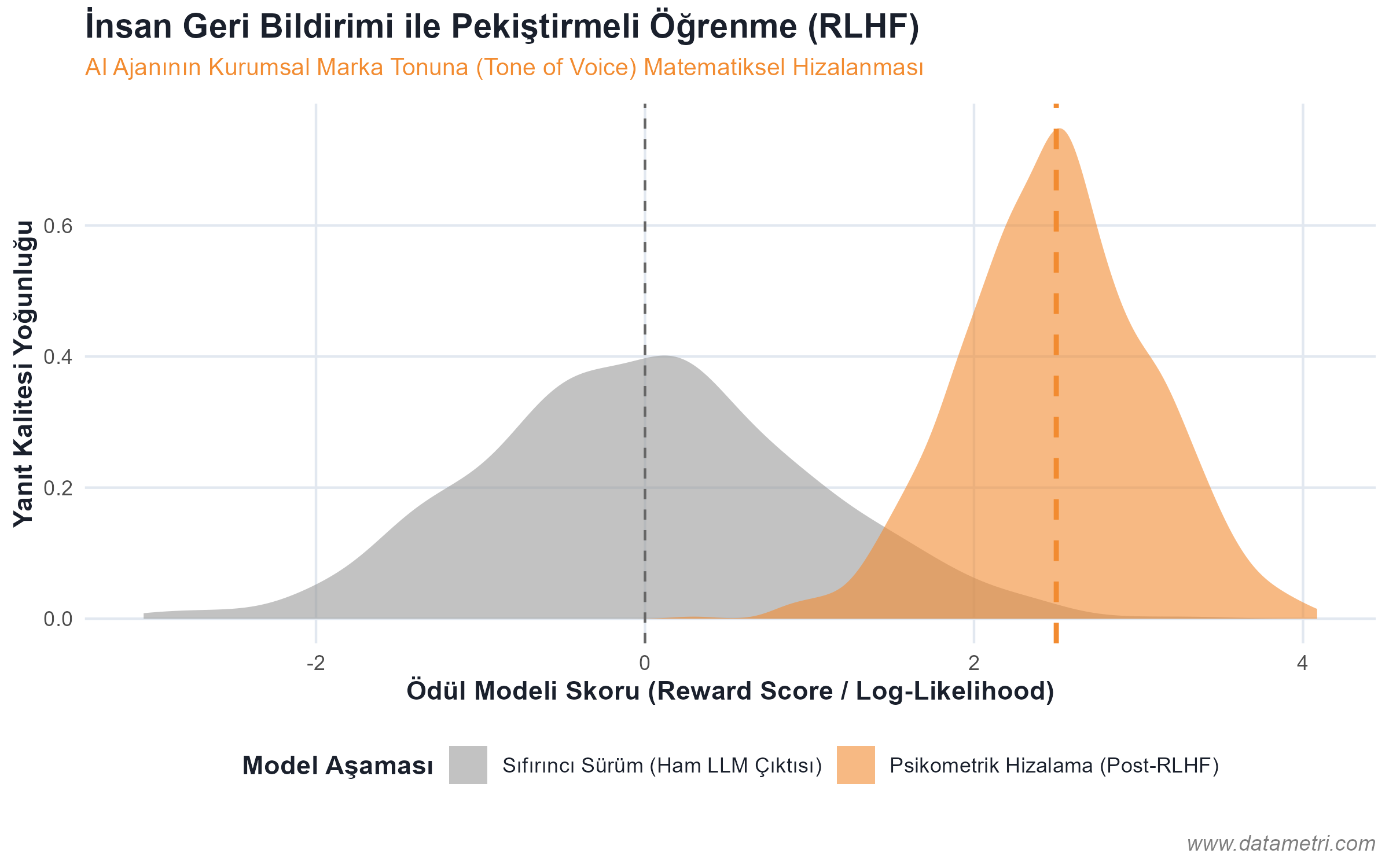
Bir yapay zeka ajanının, kurumunuzun spesifik (domain-specific) kurallarını doğru yorumlayabilmesi için, verinin modele "bütün bir metin" olarak değil; matematiksel bir vektör uzayında izole edilerek sunulması gerekir. Bu mimari, LLM'in genel geçer internet verisiyle (pre-trained knowledge) kurum verisini birbirine karıştırmasını engeller.
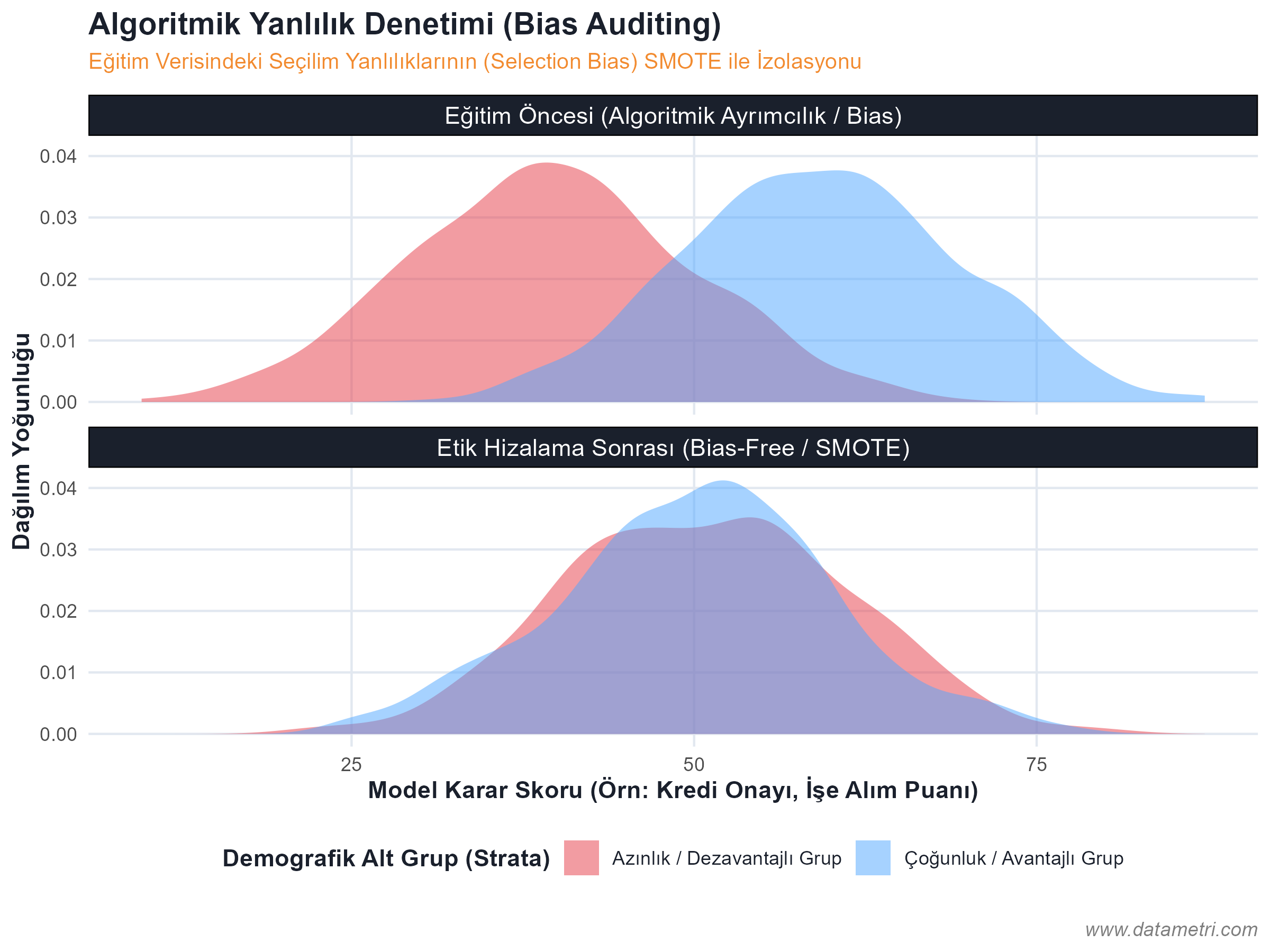
İzole Edilen Yanlılıklar ve Metodolojik Karşı Önlemler
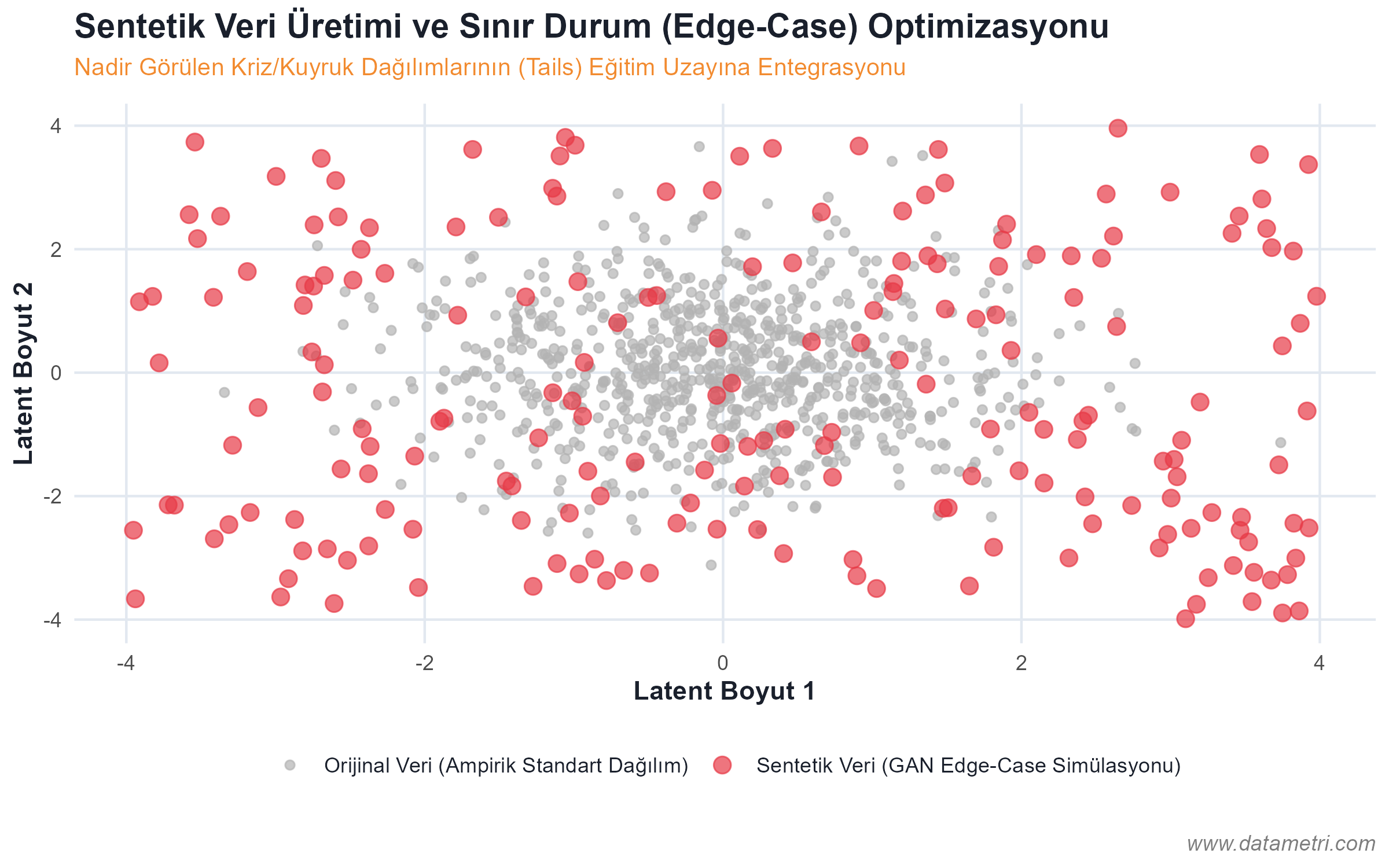
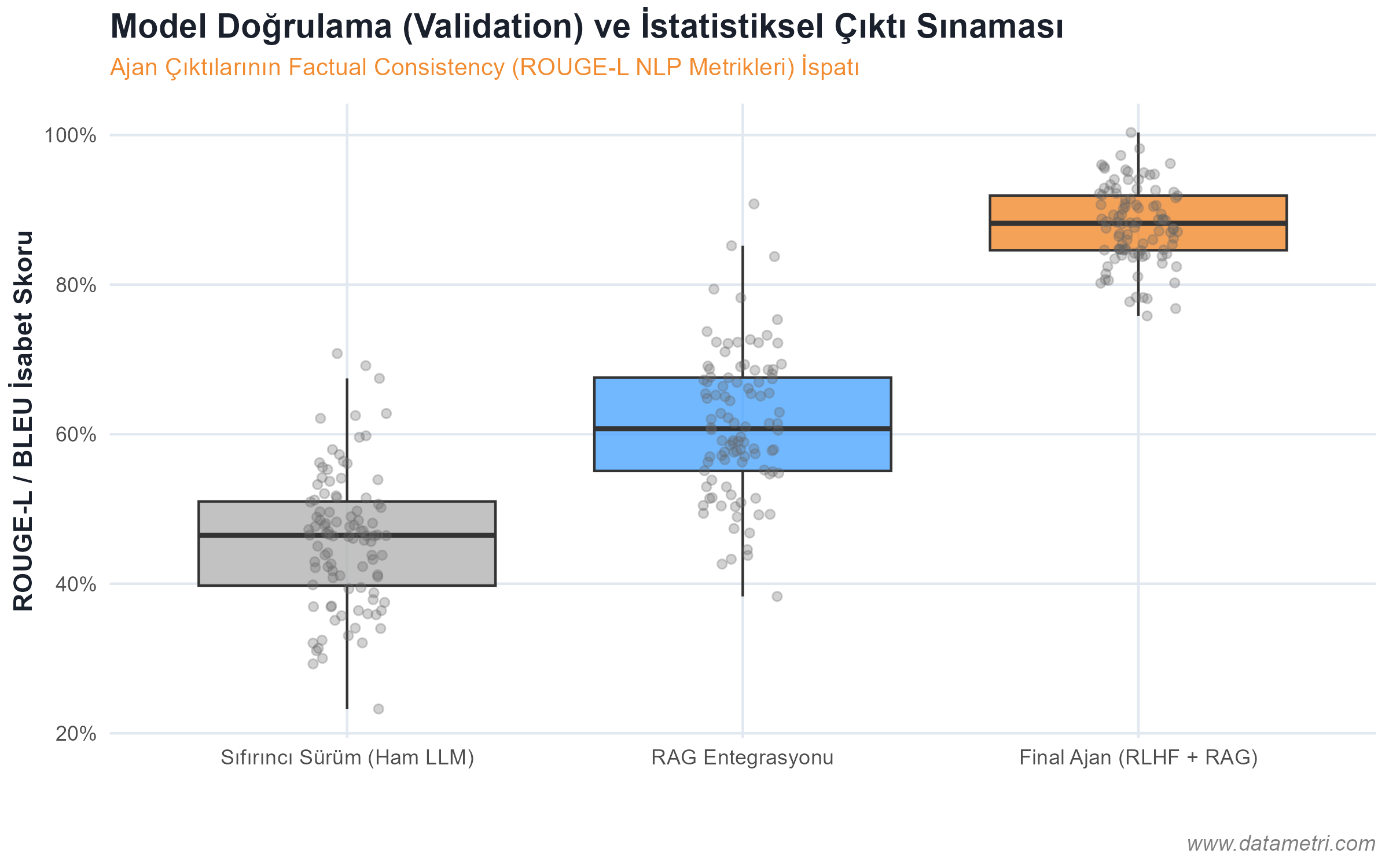
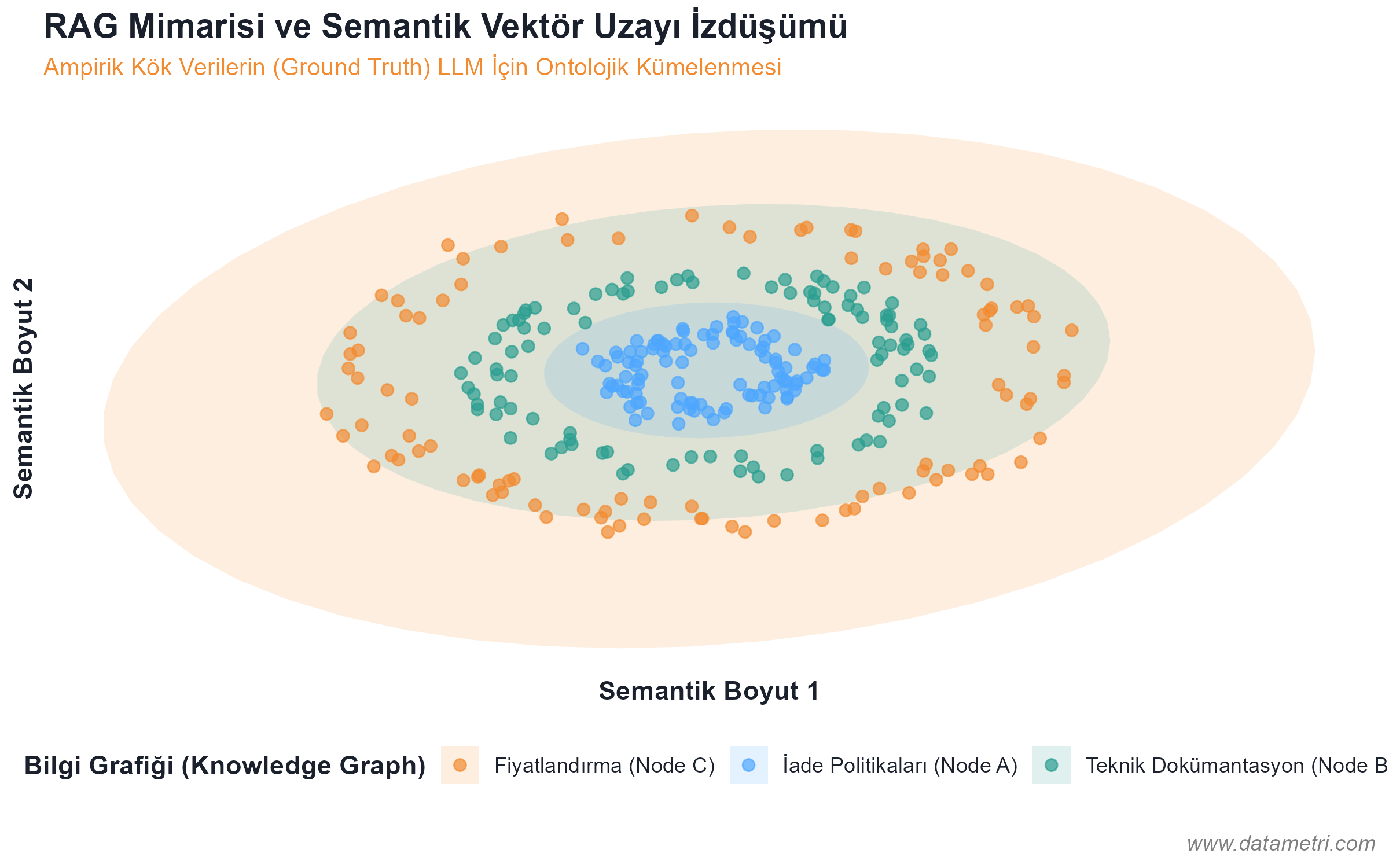
- Halüsinasyonun Ontolojik Kökeni: Modelin "gerçekte var olmayan" bilgileri üretmesini engellemek için, belgeleri mantıksal düğümlere (Semantic Chunking) ayırarak Vektör Veritabanlarına yerleştiriyoruz. Böylece model, cevabı ezberinden değil, doğrudan işaret edilen "Ampirik Kök Veriden (Ground Truth)" çekmeye zorlanır.
- Bilgi Grafikleri (Knowledge Graphs): RAG mimarisine entegre edilecek kavramlar arasındaki nedensellik ilişkilerini katı bir ontolojik haritayla birbirine bağlayarak modelin muhakeme (reasoning) yeteneğini algoritmik olarak kontrol altında tutuyoruz.
caption = 'www.datametri.com'
Yapay zeka ajanınızın ezbere dayalı bir "kara kutu" olmaktan çıkıp; sadece sizin kurumsal gerçekliğinizin ampirik sınırları içinde (Kapalı Sistem) çalışan istatistiksel bir determinizme kavuşmasını sağlar.